Thema 3 · Normaalverdeling & z-scores
Deel 2 — Standaardiseren · ruw is ruk, het lineaaltje
Ruw is ruk
Een egel scoort 130 op pienterheid. Is dat veel? Je hebt geen idee. Honderddertig wát? Een ruwe score op zichzelf zegt niks — je weet niet waar het midden ligt, niet hoe uitgesmeerd de groep is, niet of 130 zeldzaam is of doodgewoon.
Daarom: ruw is ruk. We willen een score die zichzelf uitlegt. Dat is een z-score.
Het marsmannetje
Stel je praat met een marsmannetje. Het kent de aarde niet, maar rekenen kan het wel. Je zegt: “mijn pienterheid is 130.” Daar heeft het niks aan — 130 betekent niks op Mars.
Wat heeft het marsmannetje wél nodig? Precies twee dingen:
- “Het is normaal verdeeld” — dan ziet het de bekende belcurve voor zich.
- “Ik zit 2 standaardafwijkingen rechts van het midden.”
Meer niet. Niet de 130, niet de 100, niet de 15 — die zijn allemaal ruk. Het enige dat telt is hoeveel standaardafwijkingen je van het midden zit. En dát getal is de z-score.
z = het aantal lineaaltjes
Denk aan de standaardafwijking als een lineaaltje van 15 punten. De z-score is simpelweg: hoe vaak past dat lineaaltje tussen het midden en jouw score?
\[z = \frac{x - \mu_x}{\sigma_x} = \frac{\text{specifiek} - \text{algemeen}}{\text{lineaaltje}}\]
Voor onze egel van 130: \(z = \dfrac{130 - 100}{15} = 2\). Twee lineaaltjes naar rechts. Twee wát? Twee koeien, twee moeders? Nee — twee standaardafwijkingen. Zet er altijd de tel-eenheid bij.
De normaalverdeling
Waar komt die belcurve vandaan? Denk aan een houten plank vol spijkers, rechtop gezet. Je laat boven in het midden een knikker vallen: tik-tik-tik stuitert hij tussen de spijkers naar beneden. Meestal landt hij rond het midden, soms wat extremer. Doe dat met duizend knikkers en je krijgt vanzelf die gladde bel.
Notatie: \(x \sim N(\mu, \sigma)\) — het krulletje betekent “gedraagt zich als”, de \(N\) staat voor normaal. Onze egels: pienterheid \(\sim N(100, 15)\) — lees dit als: normaal verdeeld met gemiddelde 100 en standaardafwijking 15.
De z-tabel
De z-tabel (Tabel A, de standaardnormaal) vertaalt een z-score naar een kans. Twee regels die je leven redden:
- Regel 1: téken eerst. Schets de bel, zet je z erin, arceer het stuk dat je zoekt. Kijk: heb je een twee- of een driedeling nodig? Welke staart?
- De tabel geeft altijd de linkerkant (de kans op “of lager”). Wil je de rechterstaart, doe dan 1 min de tabelwaarde — of zoek de negatieve z op, want door de symmetrie is dat hetzelfde.
De tabel verkeerd aflezen is zelden het probleem; het verkeerde gebied arceren wél. Daarom: eerst tekenen, dán pas opzoeken.
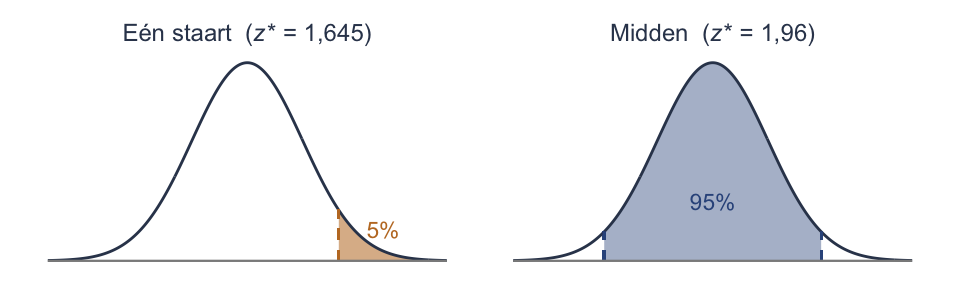
TipHeilige z-waarden (uit je hoofd)
| Eén staart | z* | Midden (tweezijdig) |
|---|---|---|
| 5% | 1,645 | 90% |
| 2,5% | 1,96 | 95% |
| 0,5% | 2,576 | 99% |
De 1,96 is de heiligste — maar let op: die hoort bij 2,5% in één staart (95% in het midden), níét bij 5% in één staart. Voor 5% in één staart is het 1,645. Teken het, dan zie je het verschil.
De richtings-engine: x ⇄ z ⇄ p
Bijna alles wat hierna komt — z-scores, betrouwbaarheidsintervallen, toetsen, power — is dezelfde wandeling, twee kanten op. Eén ketting:
\[\text{gebeurtenis } x \;\rightleftarrows\; \text{aantal lineaaltjes } z \;\rightleftarrows\; \text{kans } p\]
- \(x \to z\): “hoe ver van het midden, in lineaaltjes?” → \(z = \dfrac{x - \mu_x}{\sigma_x}\).
- \(z \to x\): “loop \(z\) lineaaltjes vanaf het midden” → \(x = \mu_x + z \cdot \sigma_x\).
- \(z \rightleftarrows p\): de z-tabel, heen of terug.
De gegeven bepaalt de richting. Krijg je een score en zoek je een kans? Dan ga je \(x \to z \to p\). Krijg je een kans (of percentage) en zoek je een score? Dan \(p \to z \to x\). Lees dus eerst: wat is gegeven, en wat moet ik hebben?
Twee soorten vragen
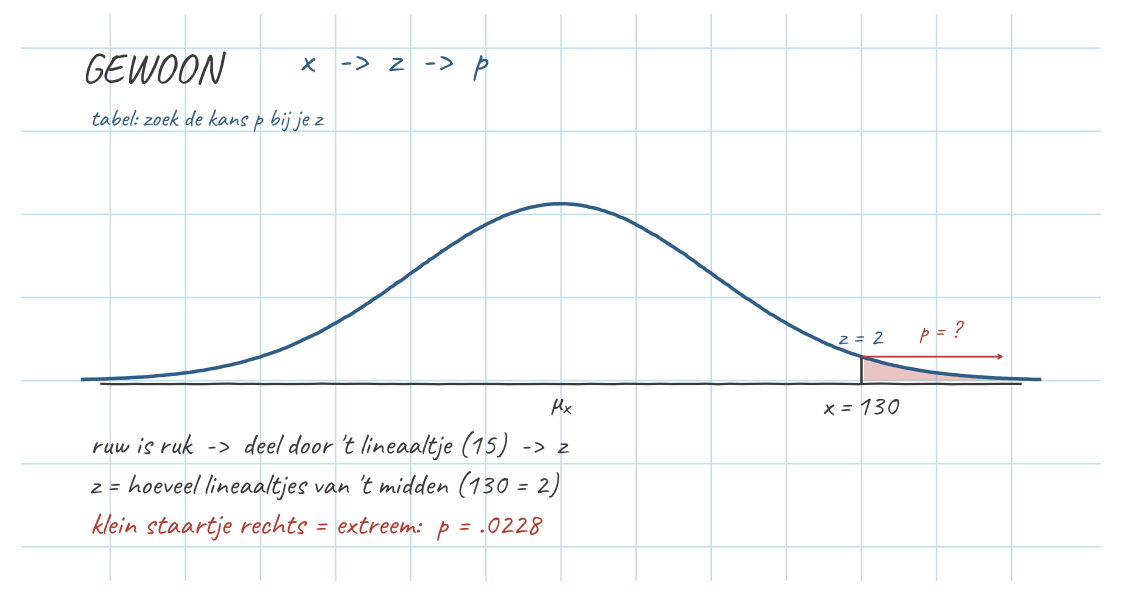
Gewoon: \(x \to z \to p\) (score gegeven, kans gezocht)
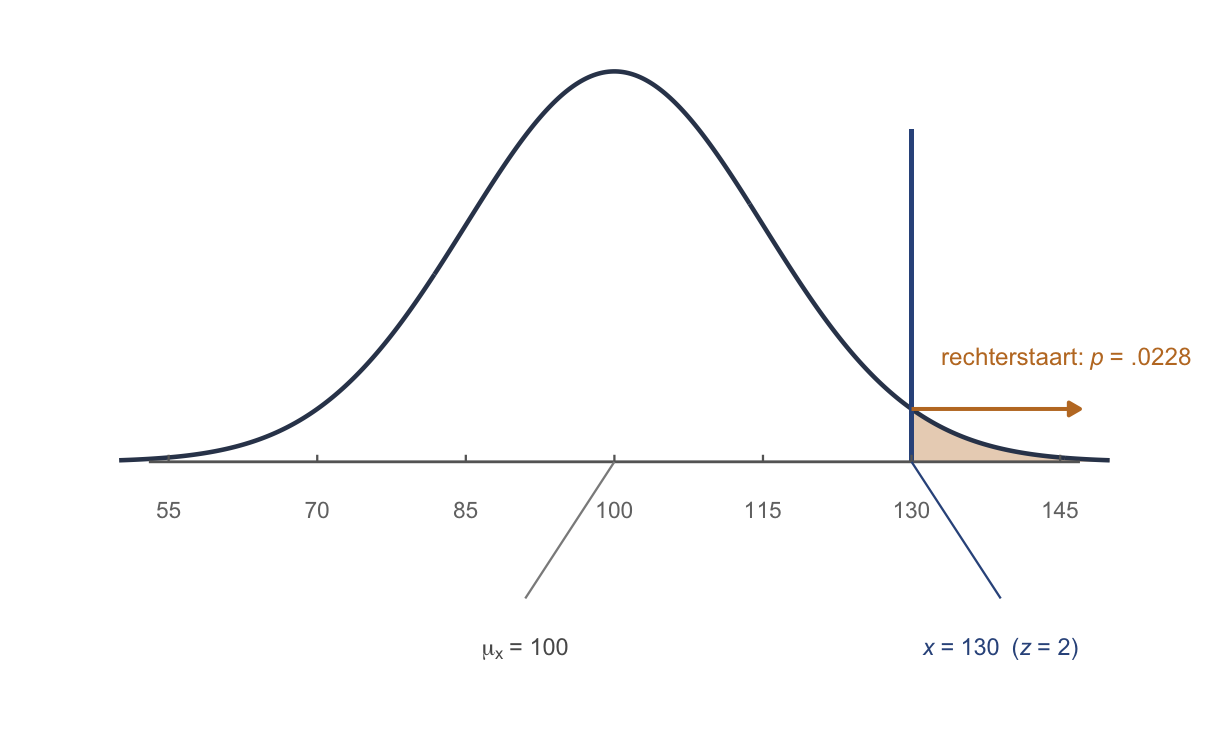
Welk deel van de egels is pienterder dan 130?
- \(z = \dfrac{130 - 100}{15} = 2{,}00\) (twee lineaaltjes rechts).
- Tabel A bij \(z = 2{,}00\): linkerkant \(= .9772\).
- We willen de rechterstaart: \(1 - .9772 = .0228\).
Dus 2,28% van de egels is pienterder dan 130. (Teken het: een klein staartje rechts — klein staartje = extreem.)
| \(i\) | egel | \(x_i\) | \(z_i = \dfrac{x_i-100}{15}\) | rechterstaart |
|---|---|---|---|---|
| 1 | A | 130 | +2,00 | .023 |
| 2 | B | 92,5 | −0,50 | .691 |
| 3 | C | 115 | +1,00 | .159 |
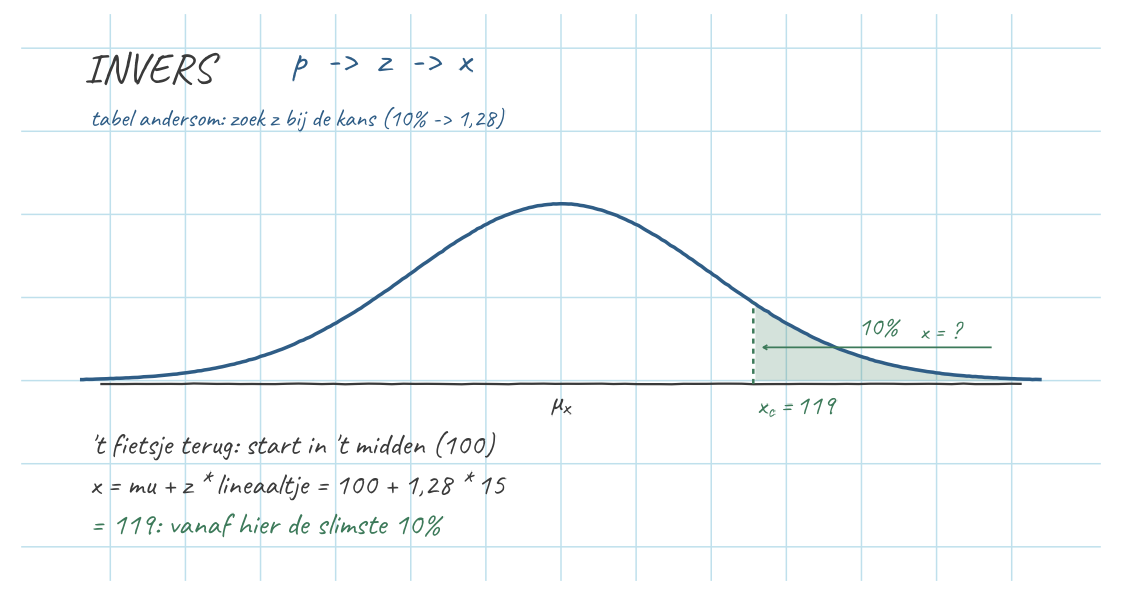
Invers: \(p \to z \to x\) (kans gegeven, score gezocht)
Boven welke pienterheid zitten de 10% slimste egels?
- 10% boven → 90% eronder → in de tabel hoort daar \(z \approx 1{,}28\) bij.
- Loop terug: \(x = \mu_x + z\cdot\sigma_x = 100 + 1{,}28 \cdot 15 = 119{,}2\).
Dus vanaf zo’n 119 behoor je tot de slimste 10%. Zelfde fietsje, andere kant op.
Oefenen
OpgeletVolledige uitwerking T3.3 — stap voor stap
Bij een tussen-vraag pak je nooit de twee staarten los; je pakt de grote oppervlakte min de kleine. Drie stapjes:
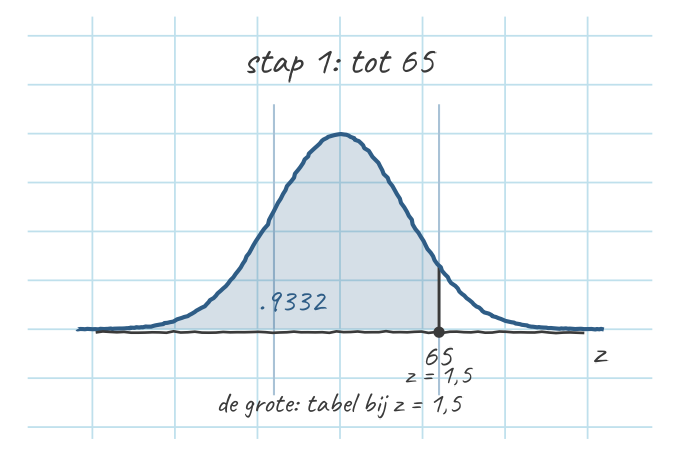
- Alles tot 65 (de grote): \(z_{65} = +1{,}50\) → Tabel A geeft \(p(z \le 1{,}50) = .9332\). Dat is alles links van 65.
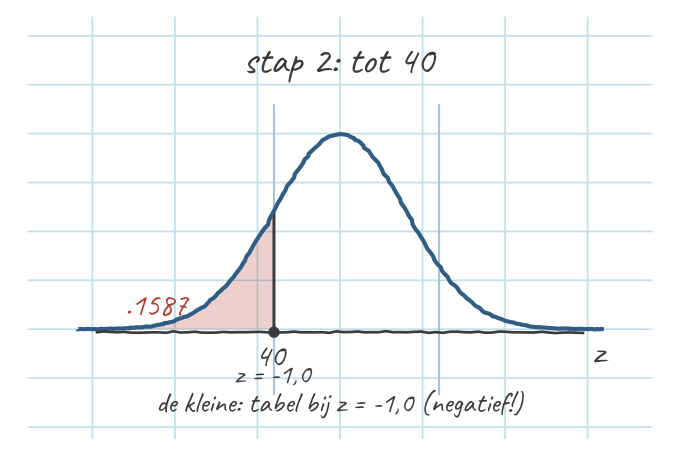
- Alles tot 40 (de kleine): \(z_{40} = -1{,}00\) → let op: negatief, want 40 ligt links van het gemiddelde. \(p(z \le -1{,}00) = .1587\). Dat is alles links van 40.
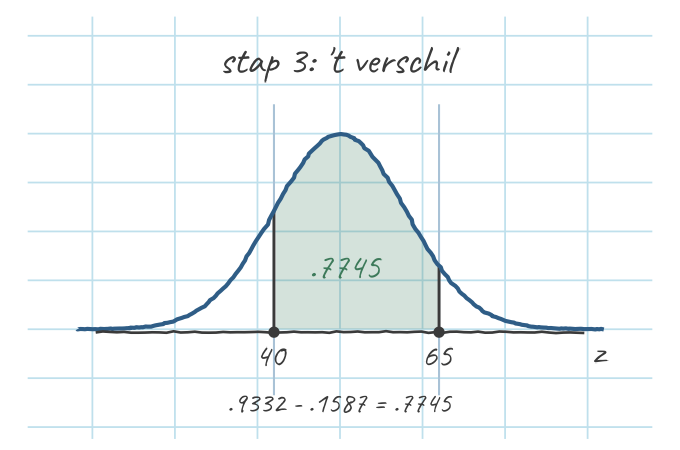
- Het verschil = de band ertussen: \(.9332 - .1587 = .7745\).
Dus zo’n 77% van de uilen zit qua alertheid tussen 40 en 65. Val op: bij “tussen” trek je af (niet optellen), en één van je twee z’s is bijna altijd negatief.
Zo ziet dat eruit — de grote oppervlakte, de kleine eraf, en wat overblijft. Onder elkaar, zodat je het aftrekken ziet:
(Steiger-schetsen; eindversie met de hand in het boek. Bron: _schetsen/schetsen_h3.R.)
Wat blijft liggen
Tot nu toe standaardiseren we de score van één individu — het lineaaltje is dan \(\sigma_x\). Straks (Deel 4) kijken we niet naar één egel maar naar een heel steekproefgemiddelde; dan wordt het lineaaltje de standaardfout \(\sigma_{\bar{x}} = \sigma_x/\sqrt{n}\). De wandeling x ⇄ z ⇄ p blijft exact hetzelfde — alleen het lineaaltje verandert.
Tot slot
130 zegt het marsmannetje niks; “twee lineaaltjes rechts” zegt het alles. Dáár zit de hele truc: niet de ruwe score, maar hoe vaak je lineaaltje ertussen past. Onthoud dat lineaaltje en het fietsje, want vanaf hier verandert er bijna niks meer — élke toets, élk interval, straks de power, het is telkens ditzelfde fietsje. Alleen het lineaaltje wisselt af en toe van lengte.
Werkboek OZP 1 · Thema 3, versie 0.1 (handrekenen & theorie). Doorlopend voorbeeld: de egels.