Van z naar t: σ kennen we nooit
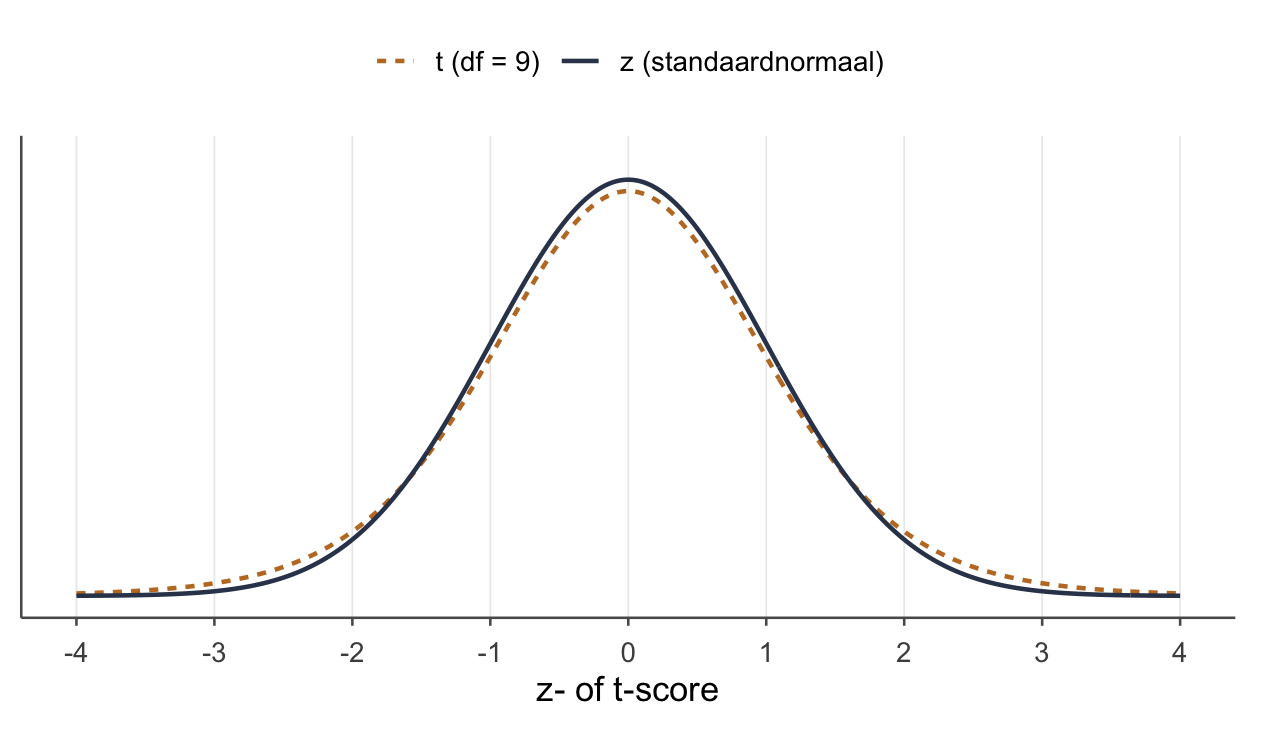
In thema 8 deden we alsof we \(\sigma_x\) kennen. Dat is een prettige fictie voor het uitleggen, maar in de echte wereld komt zo’n populatie-standaardafwijking nooit kant-en-klaar binnenwaaien. We schatten \(\sigma_x\) met de standaardafwijking van onze steekproef: \(s_x\). En dat extra schatten kost ons iets — vandaar een nieuwe verdeling: de t-verdeling.
Zelfde context als thema 8: pienterheid, \(H_0: \mu_x = 100\), \(H_1: \mu_x > 100\), \(\alpha = .05\), steekproef van \(n = 25\) egels met \(\bar{x} = 106\). Maar nu: \(\sigma_x\) kennen we niet (alleen God kende ’m). We hebben \(s_x = 15\) uit de steekproef — onze beste gok.
Wat verandert er?
Drie dingen, en eigenlijk maar drie:
- De standaardfout wordt geschat: \(SE_{\bar{x}} =s_x / \sqrt{n}\) in plaats van \(\sigma_x / \sqrt{n}\).
- De toetsingsgrootheid heet \(t\) in plaats van \(z\) — zelfde formule, andere naam: \(t = \dfrac{\bar{x} - \mu_0}{SE_{\bar{x}}}\).
- We zoeken de kans op in de t-verdeling met \(n-1\) vrijheidsgraden (\(df\)), niet in de z-tabel.
Voor onze egels: \(SE_{\bar{x}} =15/\sqrt{25} = 3\) (toevallig gelijk aan thema 8 — handig voor het vergelijken). \(df = n - 1 = 24\).
De snelle weg (3 regels, overzicht)
Voor de egels (\(\bar{x} = 106\), \(s_x = 15\), \(n = 25\), \(\mu_0 = 100\), eenzijdig, \(\alpha = .05\)):
- Standaardiseer: \(t = \dfrac{\bar{x} - \mu_0}{SE_{\bar{x}}} = \dfrac{106 - 100}{3} = 2{,}00\) met \(df = 24\).
- Zoek de kans: \(p = .028\) (rechterstaart, t-tabel df = 24). \(p < .05\).
- Beslis: verwerp de nulhypothese.
Conclusie: ook zonder \(\sigma_x\) als cadeau scoren egels significant boven de norm van 100. Klaar.
De lange weg — het toets-stappenplan
Stap 1 · Onderzoeksvraag. Zijn egels pienterder dan de norm van 100?
Stap 2 · Hypothesen. \(H_0: \mu_x = 100\). \(H_1: \mu_x > 100\) (rechtszijdig).
Stap 3 · Toetskeuze. Eén gemiddelde, \(\sigma_x\) onbekend → één-steekproefs t-toets (in plaats van z).
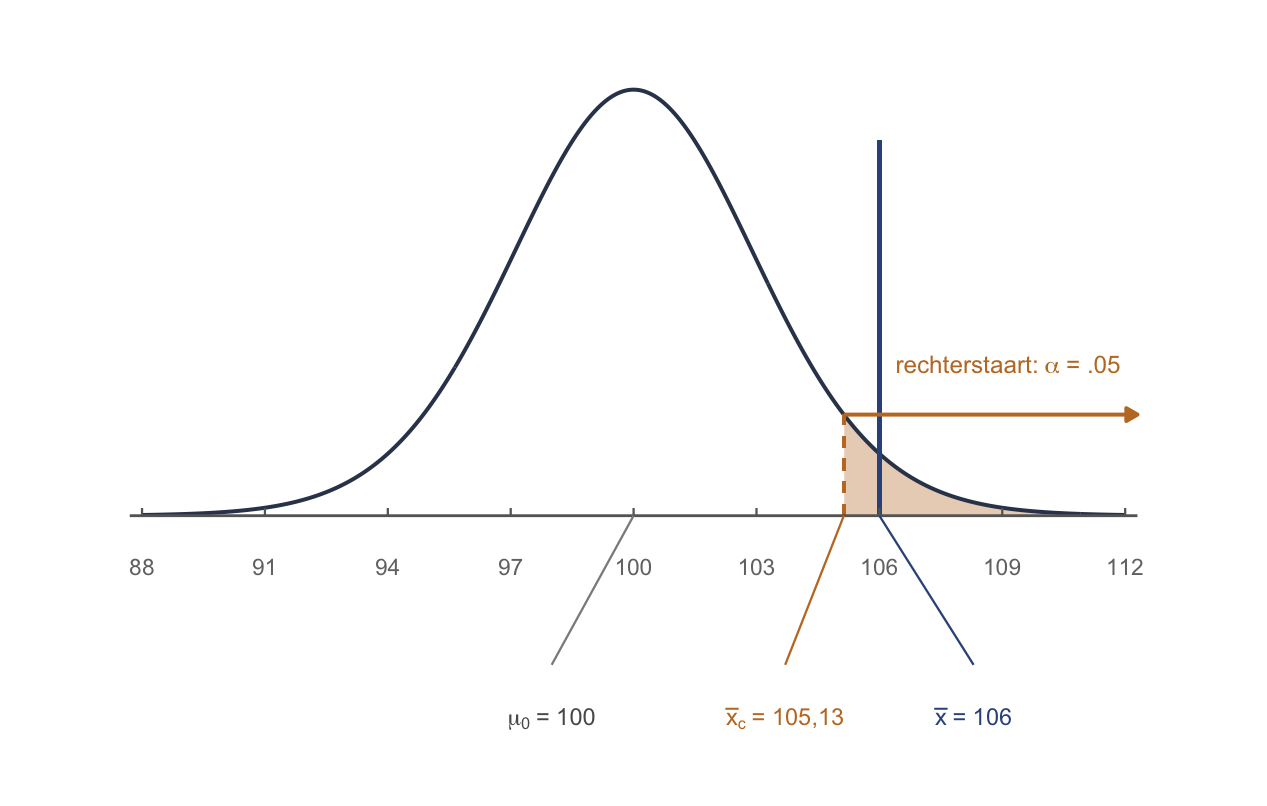
Stap 4 · Laat \(H_0\) waar zijn en teken de steekproevenverdeling. Onder \(H_0\) ligt het centrum op \(\mu_0 = 100\) met geschatte standaardfout \(SE_{\bar{x}} =15/\sqrt{25} = 3\). De rechterstaart van 5% (= \(\alpha\)) is het verwerpingsgebied — maar nu met t (df = 24), niet met z:
Stap 5 · Toetsingsgrootheid. \(t = \dfrac{\bar{x} - \mu_0}{SE_{\bar{x}}} = \dfrac{106 - 100}{3} = 2{,}00\).
Stap 6 · p-waarde of kritieke waarde.
- p-waarde: in de t-tabel bij \(df = 24\) hoort bij \(t = 2{,}00\) een eenzijdige \(p \approx .028\). (Vergelijk T8: voor \(z = 2{,}00\) was \(p = .023\). T levert iets hogere \(p\) — de dikkere staart.)
- Kritieke waarde: bij \(\alpha = .05\) eenzijdig en \(df = 24\) is \(t^* = 1{,}711\). Dus \(\bar{x}_c = 100 + 1{,}711 \cdot 3 = 105{,}13\). De gevonden \(\bar{x} = 106 > 105{,}13\) → verwerpen.
Stap 7 · Statistische beslissing. Verwerp de nulhypothese (\(t = 2{,}00\), \(df = 24\), \(p = .028\), eenzijdig, \(\alpha = .05\)).
Stap 8 · Inhoudelijke conclusie. Bij egels ligt de gemiddelde pienterheid significant boven de norm van 100 — ook nu we \(\sigma_x\) niet kenden en met \(s_x\) moesten werken.
Data om mee te spelen: egels_pienterheid.sav — of de hele zip. Met de data per egel in een kolom doe je dezelfde toets met een paar klikken:
Analyze → Compare Means → One-Sample T Test → variabele naar Test Variable(s) → bij Test Value je norm (hier 100) invullen → OK.
Aflezen: kolom \(t\), \(df\) en Sig. (de p-waarde). Let op: SPSS geeft tweezijdig — voor een eenzijdige toets deel je die p door 2.
De t-tabel is anders opgebouwd dan de z-tabel: je zoekt in de kolom een tail-percentage (5%, 2,5%, …) en in de rij je \(df\) — daar staat de kritieke \(t^*\). (Bij de z-tabel zoek je in het binnenwerk een kans-bij-een-z; de t-tabel is bewust korter.) In schema:
- z-tabel: \(z \;\to\;\) kans
- t-tabel: \(df\) + staartpercentage \(\;\to\;\) kritieke \(t^*\) Voor \(df = 24\) en eenzijdig 5%: \(t^* = 1{,}711\). Voor \(df \to \infty\) zie je 1,645 staan — exact de z-waarde. Dat is dezelfde “procenten-rij” als het college gebruikt; alleen vraag jij ’m rechtstreeks (“welke \(t\) bij 5% in één staart bij df = 24?”) in plaats van via de p-waarde.
Het t-betrouwbaarheidsinterval
Net als in thema 7 kun je rond \(\bar{x}\) een interval bouwen, maar nu met \(t^*\) in plaats van \(z^*\) en met \(SE_{\bar{x}}\) in plaats van \(\sigma_{\bar{x}}\):
\[\bar{x} \pm t^* \cdot SE_{\bar{x}}\]
Voor 95% tweezijdig bij \(df = 24\): \(t^* = 2{,}064\) (uit de t-tabel). Dus \(106 \pm 2{,}064 \cdot 3 = 106 \pm 6{,}19 = [99{,}81\,;\,112{,}19]\). Iets breder dan T8’s \(z\)-CI \([100{,}12\,;\,111{,}88]\) — de prijs van het schatten. Let op: hier ligt 100 wél nét binnen het interval — dus bij een tweezijdige toets (\(\alpha = .05\), \(H_1: \mu \neq 100\)) zou je deze nét niet verwerpen. Eenzijdig wel.
Toets je tweezijdig (\(H_1: \mu_x \neq 100\))? Dan geldt precies de regel uit T8, ook bij \(t\):
- p-waarde-methode: zoek één staart op in de t-tabel en doe ×2 (Pippi) — zo matcht het SPSS, dat een tweezijdige \(p\) teruggeeft. (Andersom: SPSS geeft die \(p\) al tweezijdig, dus voor een eenzijdige toets deel je ’m juist door 2.)
- kritieke-waarde-methode: deel \(\alpha\) door 2 → ½α = .025 per kant → zoek \(t^*\) bij .025. Géén Pippi hier; het is al per kant gesplitst.
Kort: Pippi (×2) ⇒ p-waarde; ½α per kant ⇒ kritieke waarde.
Twee andere t-toetsen — kort
Tot nu toe één steekproef tegen een norm. In de echte wereld vergelijk je vaker twee dingen. Oriëntatie, geen toetsstof voor nu: je hoeft de formules hieronder nog niet te kunnen toepassen — herken vooral het patroon (een verschil delen door zijn standaardfout).
Wanneer? Je vergelijkt twee verschillende groepen op één variabele (bijv. egels vs marmotten op pienterheid). \(H_0: \mu_1 = \mu_2\).
Formule (pooled): \(t = \dfrac{\bar{x}_1 - \bar{x}_2}{SE_{\text{verschil}}}\) met \(SE_{\text{verschil}} = s_p\sqrt{\tfrac{1}{n_1} + \tfrac{1}{n_2}}\) en \(s_p\) de “samengetrokken” SD; \(df = n_1 + n_2 - 2\).
De rest van het stappenplan blijft hetzelfde — verwacht onder \(H_0\) verschil = 0, kijk hoe ver je af zit in \(SE_{\bar{x}}\)-lineaaltjes.
Wanneer? Je hebt twee metingen aan dezelfde eenheden (bijv. egel-pienterheid vóór en ná een training). Bereken per egel het verschil \(d_i = y_{i,\text{na}} - y_{i,\text{voor}}\), en toets of dat verschil 0 is.
Formule: doe een gewone één-steekproefs t-toets op de verschillen: \(t = \bar{d}/(s_d/\sqrt{n})\) met \(df = n - 1\).
Trucje: gepaard reduceert de variatie tussen egels (elke egel is z’n eigen controle) → vaak meer power dan een onafhankelijke t op dezelfde data.
In OZP 1 oefen je vooral de één-steekproefs versie; de andere twee komen verderop in je studie. De gedachte is steeds dezelfde: een verschil delen door zijn standaardfout, en kijken hoe extreem dat is onder \(H_0\).
Oefenen
Bij een steekproef van \(n = 16\) leerlingen op een nieuwe leesvaardigheidstoets vind je \(\bar{x} = 54\), \(s_x = 8\). De landelijke norm is \(\mu_0 = 50\). Toets eenzijdig (\(H_1: \mu > 50\)) bij \(\alpha = .05\).
Wat is \(SE_{\bar{x}}\) en \(df\)?
Wat is \(t\)?
De kritieke waarde \(t^*\) bij eenzijdig \(\alpha = .05\), \(df = 15\) is 1,753. Verwerpen?
(a) \(SE_{\bar{x}} =8/\sqrt{16} = 2\). \(df = 16 - 1 = 15\).
(b) \(t = \dfrac{54 - 50}{2} = 2{,}00\).
(c) \(t = 2{,}00 > 1{,}753\) → verwerp de nulhypothese. De leerlingen scoren significant boven de landelijke norm (\(t = 2{,}00\), \(df = 15\), eenzijdig, \(\alpha = .05\)).
Data: leesvaardigheid.sav — 16 leerlingen, één kolom leesscore.
Analyze → Compare Means → One-Sample T Test → zet leesscore bij Test Variable(s) → vul bij Test Value de norm 50 in → OK.
Aflezen: t = 2,00, df = 15, en Sig. (2-tailed). SPSS geeft de p tweezijdig; onze toets is eenzijdig, dus deel die Sig. door 2. Je vindt exact je handwerk terug — en de toets verwerpt \(H_0\).
Met diezelfde steekproef (\(\bar{x} = 54\), \(s_x = 8\), \(n = 16\)): bouw het 95%-betrouwbaarheidsinterval voor \(\mu_x\). Gebruik \(t^*_{\text{tweezijdig},.05,df=15} = 2{,}131\). Ligt 50 erin?
\(SE_{\bar{x}} =2\). Foutenmarge \(M = 2{,}131 \cdot 2 = 4{,}26\). Interval: \(54 \pm 4{,}26 = [49{,}74\,;\,58{,}26]\). 50 ligt erin (maar nét). Bij een tweezijdige toets zou je dus niet verwerpen — terwijl je eenzijdig wél verwerpt. Dezelfde val als in T8: kies één-/tweezijdig vooraf en met onderbouwing.
Data: leesvaardigheid.sav — dezelfde 16 leerlingen als T9.1, kolom leesscore (\(\bar{x} = 54\), \(s = 8\)).
Analyze → Compare Means → One-Sample T Test → leesscore bij Test Variable(s) → Test Value 50 → eventueel bij Options… het Confidence Interval Percentage op 95 → OK.
Aflezen: het 95% Confidence Interval of the Difference geeft \([-0{,}26\,;\,8{,}26]\) — dat is het interval rond het verschil met 50. Tel de testwaarde 50 er weer bij op en je krijgt \([49{,}74\,;\,58{,}26]\), exact je handwerk. Dat 0 nét binnen het verschil-interval ligt (en 50 dus binnen het score-interval) is precies waarom je tweezijdig níét zou verwerpen.
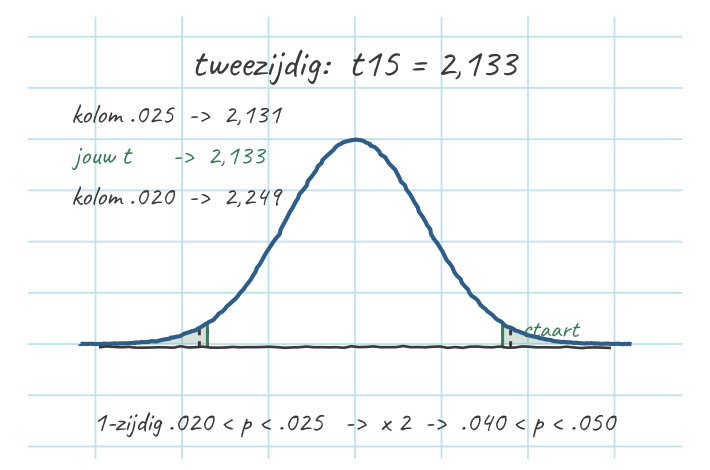
De kraaien staan bekend als de brutaaltjes van het bos, maar zijn ze ook pienterder of juist dommer dan de norm van \(\mu_0 = 100\)? Je vangt \(n = 16\) kraaien, laat ze de pienterheidstoets doen en vindt \(\bar{x} = 108\) met \(s_x = 15\) (de standaardafwijking in deze steekproef — dus \(\sigma_x\) onbekend). Toets tweezijdig op \(\alpha = .05\) of kraaien gemiddeld afwijken van 100.
- \(H_0: \mu_x = 100\)
- \(H_1: \mu_x \neq 100\) — uit de vraag “anders dan 100?”, niet uit je steekproef
- \(SE_{\bar{x}} = 15/\sqrt{16} = 3{,}75\)
- \(t_{15} = \dfrac{108 - 100}{3{,}75} = 2{,}133\)
- \(df = 16 - 1 = 15\)
- t-tabel, rij \(df = 15\): \(2{,}133\) ligt tussen \(2{,}131\) (kolom .025) en \(2{,}249\) (kolom .020) → eenzijdig \(.020 < p < .025\)
- Tweezijdig → ×2: \(.040 < p < .050\)
- \(p \leq \alpha\ (.05)\) → \(H_0\) verwerpen
- Antwoord: kraaien scoren gemiddeld significant anders (hier: hoger) dan de norm van 100
- \(H_0\) / \(H_1\) uit de vraag. Streep het vraagteken weg → de stellende zin “kraaien zijn anders dan 100” is je \(H_1\); \(H_0\) is de ontkenning. (Nooit uit je steekproef aflezen — de 108 mag de richting niet bepalen.) Dus, onder elkaar:
\(H_0: \mu_x = 100\)
\(H_1: \mu_x \neq 100\)
- Toetskeuze. Eén gemiddelde, \(s_x\) komt uit de steekproef → \(\sigma_x\) onbekend → één-steekproefs t-toets.
- Standaardfout. \(SE_{\bar{x}} = s_x/\sqrt{n} = 15/\sqrt{16} = 15/4 = 3{,}75\).
- Toetsingsgrootheid. \(t_{15} = \dfrac{\bar{x} - \mu_0}{SE_{\bar{x}}} = \dfrac{108 - 100}{3{,}75} = 2{,}133\) (op 3 decimalen, zodat je ’m makkelijk in de tabel matcht). \(df = n - 1 = 15\).
- Opzoeken = een range, geen exacte \(p\). Ga naar rij \(df = 15\). Je \(t = 2{,}133\) valt tussen twee tabelwaarden: \(2{,}131\) (onder kolom .025) en \(2{,}249\) (onder kolom .020). Grotere \(t\) → kleinere \(p\), dus je eenzijdige kans zit tussen die twee kolom-\(p\)’s: \(.020 < p < .025\).
- Tweezijdig → ×2 (Pippi). Je \(H_1\) heeft twee kanten (\(\neq\)), dus twee even grote staartjes: verdubbel de eenzijdige range. \(.020 \times 2 = .040\) en \(.025 \times 2 = .050\), dus \(.040 < p < .050\).
- Beslissen — when p is low, \(H_0\) must go: de hele range ligt op of onder \(\alpha = .05\), dus \(p \leq .05\) → verwerp \(H_0\).
- Conclusie. Kraaien wijken gemiddeld significant af van de norm (\(t = 2{,}133\), \(df = 15\), tweezijdig, \(\alpha = .05\)); met \(\bar{x} = 108\) scoren ze hoger dan 100. Pas hier, in de conclusiezin, mag je desnoods zeggen “een kans van minder dan 5%” — in de berekening zelf hield je netjes de proportie \(p\) aan.
De boswachter beweert dat de wezels dit jaar gemiddeld hoger dan \(\mu_0 = 6{,}5\) scoren op de foerageertoets. Bij \(n = 30\) wezels vind je \(\bar{x} = 7\) met \(s_x = 1{,}2\). Toets eenzijdig (rechts) op \(\alpha = .05\).
- \(H_0: \mu_x = 6{,}5\)
- \(H_1: \mu_x > 6{,}5\) — uit de vraag “hoger dan 6,5?”
- \(SE_{\bar{x}} = 1{,}2/\sqrt{30} = 0{,}219\)
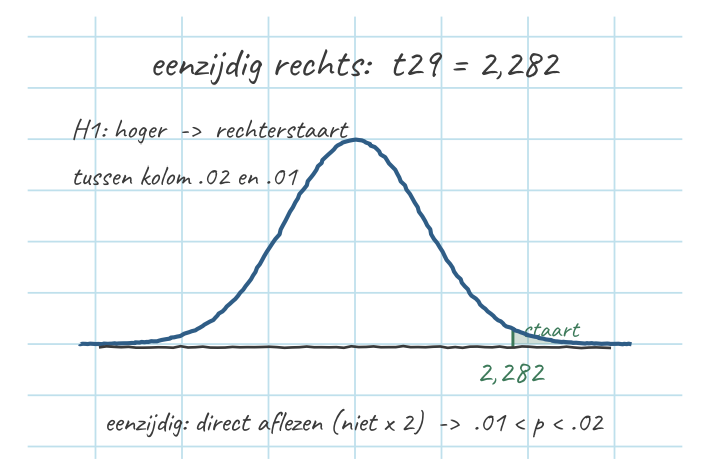
- \(t_{29} = \dfrac{7 - 6{,}5}{0{,}219} = 2{,}282\)
- \(df = 30 - 1 = 29\)
- Rechterstaart (want \(H_1\) “hoger”), rij \(df = 29\): \(2{,}282\) ligt tussen \(2{,}150\) (kolom .02) en \(2{,}462\) (kolom .01) → \(.01 < p < .02\)
- Eenzijdig → géén ×2
- \(p \leq \alpha\ (.05)\) → \(H_0\) verwerpen
- Antwoord: wezels scoren gemiddeld significant hoger dan 6,5
- \(H_0\) / \(H_1\) uit de vraag. Vraagteken weg → “wezels scoren hoger dan 6,5” = \(H_1\); \(H_0\) is de ontkenning. Dus:
\(H_0: \mu_x = 6{,}5\)
\(H_1: \mu_x > 6{,}5\)
- Toetskeuze. Eén gemiddelde, \(s_x\) uit de steekproef → één-steekproefs t-toets.
- Standaardfout. \(SE_{\bar{x}} = 1{,}2/\sqrt{30} = 1{,}2/5{,}477 = 0{,}219\).
- Toetsingsgrootheid. \(t_{29} = \dfrac{7 - 6{,}5}{0{,}219} = 2{,}282\); \(df = n - 1 = 29\).
- Welke staart? Uit de \(H_1\), niet uit het teken. \(H_1\) zegt “hoger” → rechterstaart. (Dat \(t\) positief uitkomt, bevestigt dat alleen maar.)
- Opzoeken = een range. Rij \(df = 29\): \(t = 2{,}282\) valt tussen \(2{,}150\) (kolom .02) en \(2{,}462\) (kolom .01). Dus \(.01 < p < .02\).
- Eenzijdig → géén ×2. Er is maar één staart in het spel, dus je leest de kolom-\(p\)’s direct af — niet verdubbelen.
- Beslissen. \(p \leq .02 < \alpha\ (.05)\) → when p is low, \(H_0\) must go → verwerp \(H_0\).
- Conclusie. De wezels scoren gemiddeld significant hoger dan de norm van 6,5 (\(t = 2{,}282\), \(df = 29\), eenzijdig, \(\alpha = .05\)).
De vossen zouden dit seizoen juist lager dan \(\mu_0 = 5{,}5\) scoren op de sluwheidstoets — te veel afleiding bij het kippenhok. Bij \(n = 25\) vossen vind je \(\bar{x} = 4{,}8\) met \(s_x = 1{,}2\). Toets eenzijdig (links) op \(\alpha = .05\).
- \(H_0: \mu_x = 5{,}5\)
- \(H_1: \mu_x < 5{,}5\) — uit de vraag “lager dan 5,5?”
- \(SE_{\bar{x}} = 1{,}2/\sqrt{25} = 0{,}24\)
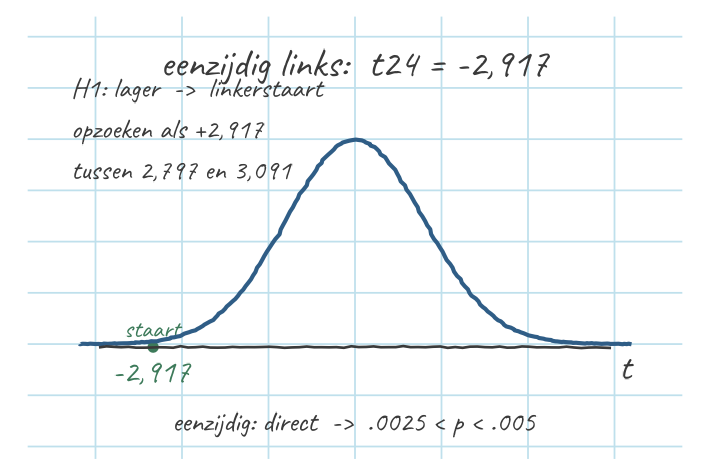
- \(t_{24} = \dfrac{4{,}8 - 5{,}5}{0{,}24} = -2{,}917\)
- \(df = 25 - 1 = 24\)
- Linkerstaart (want \(H_1\) “lager”); negatieve \(t\) opzoeken als \(+2{,}917\)
- Rij \(df = 24\): \(2{,}917\) ligt tussen \(2{,}797\) (kolom .005) en \(3{,}091\) (kolom .0025) → \(.0025 < p < .005\)
- Eenzijdig → géén ×2
- \(p \leq \alpha\ (.05)\) → \(H_0\) verwerpen
- Antwoord: vossen scoren gemiddeld significant lager dan 5,5
- \(H_0\) / \(H_1\) uit de vraag. Vraagteken weg → “vossen scoren lager dan 5,5” = \(H_1\); \(H_0\) is de ontkenning. Dus:
\(H_0: \mu_x = 5{,}5\)
\(H_1: \mu_x < 5{,}5\)
- Toetskeuze. Eén gemiddelde, \(s_x\) uit de steekproef → één-steekproefs t-toets.
- Standaardfout. \(SE_{\bar{x}} = 1{,}2/\sqrt{25} = 1{,}2/5 = 0{,}24\).
- Toetsingsgrootheid. \(t_{24} = \dfrac{4{,}8 - 5{,}5}{0{,}24} = \dfrac{-0{,}7}{0{,}24} = -2{,}917\); \(df = n - 1 = 24\). De \(t\) is negatief — logisch, want \(\bar{x}\) ligt onder \(\mu_0\).
- Welke staart? Uit de \(H_1\). \(H_1\) zegt “lager” → linkerstaart. Het minteken van \(t\) bevestigt dat.
- Negatieve \(t\) opzoeken alsof-ie positief is. De verdeling is symmetrisch, dus je zoekt \(|t| = 2{,}917\) op in dezelfde tabel. Rij \(df = 24\): \(2{,}917\) valt tussen \(2{,}797\) (kolom .005) en \(3{,}091\) (kolom .0025). Dus \(.0025 < p < .005\).
- Eenzijdig → géén ×2. Eén staart, dus de kolom-\(p\)’s direct aflezen.
- Beslissen. \(p < .005 \leq \alpha\ (.05)\) → verwerp \(H_0\).
- Conclusie. De vossen scoren gemiddeld significant lager dan de norm van 5,5 (\(t = -2{,}917\), \(df = 24\), eenzijdig, \(\alpha = .05\)).
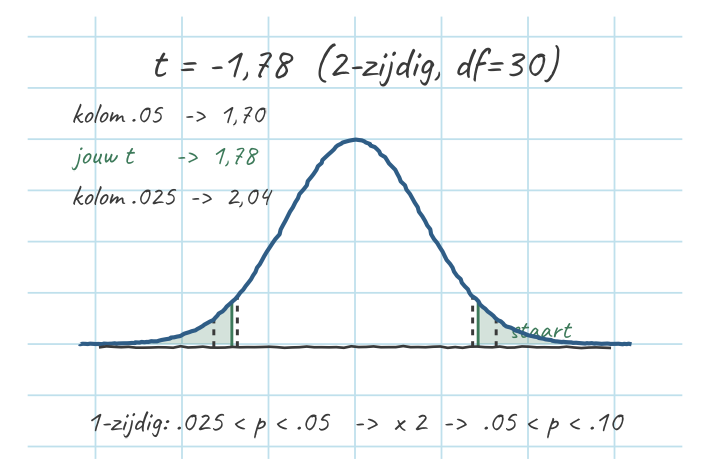
Op het tentamen (versie V24) krijg je de rekenstap al cadeau: een collega vond \(t = -1{,}78\) bij \(df = 30\) en toetste tweezijdig. Gevraagd: bepaal de \(p\)-range en beslis bij \(\alpha = .05\). (Herken de valkuil: de \(t\) is al gegeven, jij hoeft ’m alleen nog in de tabel te plaatsen en de tweezijdig-regel toe te passen.)
- Negatieve \(t\) opzoeken als \(|t| = 1{,}78\)
- Rij \(df = 30\): \(1{,}78\) ligt tussen \(1{,}697\) (kolom .05) en \(2{,}042\) (kolom .025) → eenzijdig \(.025 < p < .05\)
- Tweezijdig → ×2: \(.05 < p < .10\)
- \(p > \alpha\ (.05)\) → \(H_0\) niet verwerpen
- Antwoord: \(.05 < p < .10\); niet significant
- Wat is er gegeven? \(t = -1{,}78\), \(df = 30\), tweezijdig. Je hoeft niets meer te standaardiseren — direct de tabel in. (Ook dít is een vaardigheid: soms geeft het tentamen de \(t\) en vraagt alleen de \(p\)-range + beslissing.)
- Negatieve \(t\) opzoeken alsof-ie positief is. De \(t\)-verdeling is symmetrisch, dus je zoekt \(|t| = 1{,}78\).
- Opzoeken = een range. Rij \(df = 30\): \(1{,}78\) valt tussen \(1{,}697\) (kolom .05) en \(2{,}042\) (kolom .025). Grotere \(t\) → kleinere \(p\), dus je eenzijdige kans zit tussen die twee kolom-\(p\)’s: \(.025 < p < .05\).
- Tweezijdig → ×2 (Pippi). Verdubbel de eenzijdige range: \(.025 \times 2 = .05\) en \(.05 \times 2 = .10\), dus \(.05 < p < .10\).
- Beslissen. De hele range ligt boven \(\alpha = .05\), dus \(p > .05\) → \(H_0\) niet verwerpen. (De riedel when p is low, \(H_0\) must go gaat hier dus juist niet op: \(p\) is niet laag genoeg.)
- Conclusie. Met \(.05 < p < .10\) is het resultaat niet significant bij \(\alpha = .05\). Let op de val: was er eenzijdig getoetst, dan lag \(p\) tussen \(.025\) en \(.05\) en had je wél verworpen — kies één-/tweezijdig dus vooraf en met onderbouwing.
Wat blijft liggen
We toetsten alleen gemiddelden. In thema 10 vragen we ons af: hoe goed vángt deze toets een echt effect? — dat is power. Twee dingen uit dít thema komen daar terug. Ten eerste tekende je hier voor het eerst twee verdelingen over dezelfde as (de \(z\)- en de \(t\)-berg, figuur hierboven) — in thema 10 doe je dat opnieuw, maar dan twee wérelden: de God-berg onder \(H_0\) en de Allah-berg onder \(H_1\). Diezelfde grammatica, twee curven op één getallenlijn. Ten tweede: strikt genomen leeft de “echte” wereld in thema 10 ook in een (\(t\)-achtige) verdeling, maar we rékenen power gewoon met \(z\) — net als de snelle weg hier. De \(t\)-notatie van het college hoef je straks alleen te kunnen lézen, niet uit te rekenen. En in thema 11 stappen we over op categorieën (chi-kwadraat).
Tot slot
In thema 8 deed ik nog alsof we \(\sigma\) kenden — een prettige fictie om de toets uit te leggen, maar \(\sigma\) kennen we nóóit, dat weet alleen God. Dus knal je \(s\) erin, je beste gok uit de steekproef, en je betaalt daar een prijs voor: een tikje dikkere staarten, een lat die een héél klein eindje verder van het midden ligt. Verder verandert er niks. Zelfde formule, zelfde plaatje, zelfde acht stappen — alleen sla je nu een andere tabel open. En onthoud waar het op neerkomt: \(t\) is gewoon \(z\) die eerlijk toegeeft dat-ie de \(\sigma\) niet wist.
Werkboek OZP 1 · Thema 9, versie 0.1 (handrekenen & theorie). Doorlopend voorbeeld: de egels.
Terug naar boven