Van getallen naar categorieën
Tot nu toe verdiende elke meting een getal op een schaal: pienterheid, lengte, leeftijd. Maar veel waarnemingen zijn categorisch: bruin / grijs / zwart, geslaagd / gezakt, links / midden / rechts. Daar begin je niet met gemiddelden, maar met tellen. En daar past één toetsfamilie: de chi-kwadraat.
Twee smaken:
- Goodness-of-fit — past mijn ene categorische variabele bij een verwachte verdeling? (Eén rij.)
- Onafhankelijkheid — hangen twee categorische variabelen samen? (Een kruistabel.)
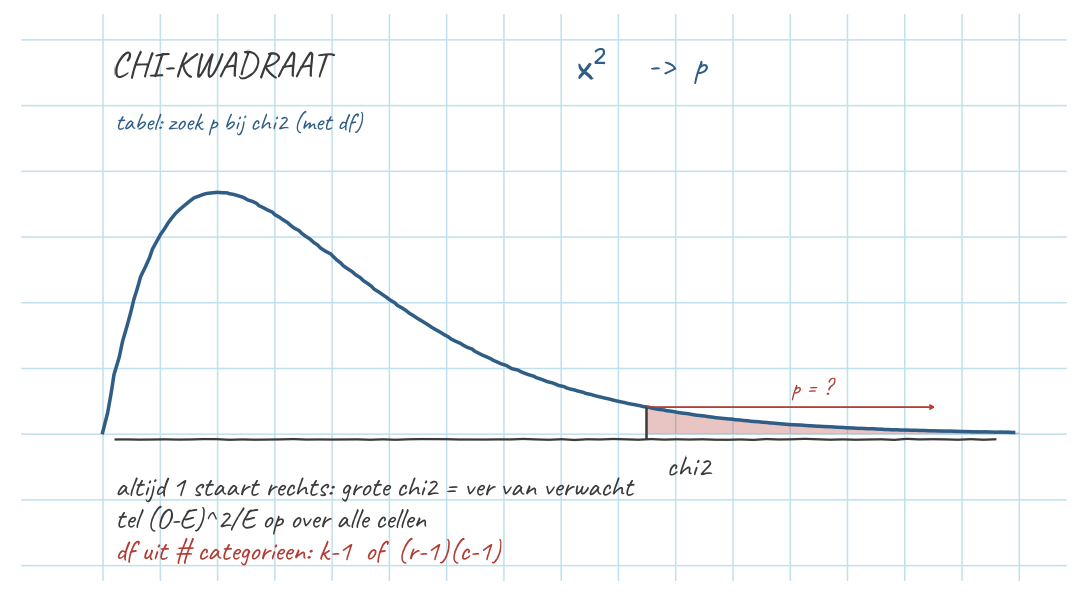
Beide draaien om hetzelfde recept: vergelijk geobserveerd met verwacht onder \(H_0\), en tel de gestandaardiseerde afwijkingen op. Het is opnieuw DATA = FIT + RESIDU: wat zien we (\(O\)), wat verwacht het model (\(E\)), en hoeveel blijft er over (\(O - E\))?
Chi-kwadraat goodness-of-fit
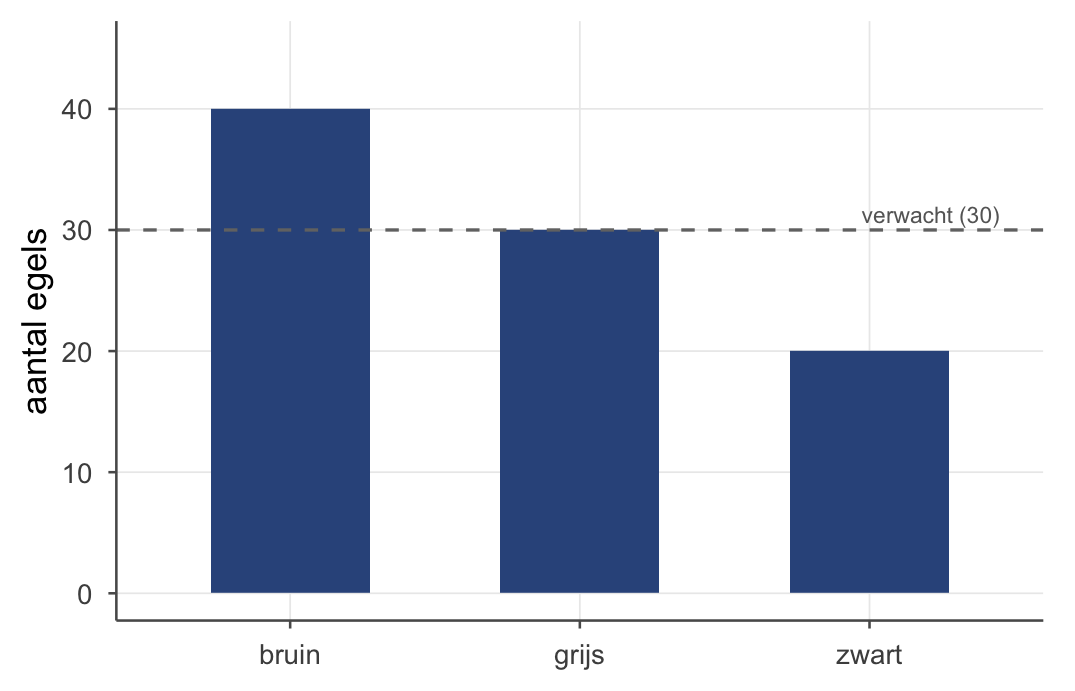
Onder egels zien we drie pelskleuren: bruin, grijs en zwart. De biologen vermoeden dat ze in de natuur gelijk verdeeld zijn (1/3 elk). Wij vangen er 90 en zien: 40 bruin, 30 grijs, 20 zwart. Klopt de gelijke verdeling, of niet?
Onder \(H_0\) (gelijke verdeling) verwachten we \(90/3 = 30\) egels per kleur. Bereken voor elke categorie het verschil en kwadrateer dat (we kwadrateren zodat plus- en min-afwijkingen elkaar niet wegvlakken — net als bij de blauwe vierkantjes van de variantie in thema 1), gedeeld door \(E\):
| bruin |
40 |
30 |
+10 |
+1,83 |
3,33 |
| grijs |
30 |
30 |
0 |
0 |
0 |
| zwart |
20 |
30 |
−10 |
−1,83 |
3,33 |
|
|
|
|
|
χ² = 6,67 |
Vrijheidsgraden: \(df = k - 1 = 3 - 1 = 2\) — de \(df\) volgt uit het aantal categorieën (\(k = 3\) kleuren), niet uit het aantal egels. Kritieke waarde \(\chi^2_{.05, df=2} = 5{,}99\) (uit de tabel). Onze 6,67 is groter → verwerp de nulhypothese: de pelskleuren zijn níét gelijk verdeeld.
Maar \(\chi^2\) zelf zegt alleen dát het patroon afwijkt — de cellen vertellen waar. Daarvoor lees je de ruwe celresiduen \(\dfrac{O-E}{\sqrt{E}}\) (de vierde kolom): bruin zit +1,83 boven verwachting, zwart −1,83 eronder, grijs precies goed. Een residu voorbij ongeveer ±2 is een opvallende cel — al is dat een ruwe vuistregel; hoe je een cel écht standaardiseert (en waarom \(\sqrt{E}\) daarvoor te grof is) zie je zo bij de kruistabel. En kwadrateer je zo’n residu, dan krijg je exact die cel z’n bijdrage aan \(\chi^2\) (\(1{,}83^2 \approx 3{,}33\)) — samen weer 6,67. Zo zie je niet alleen of het afwijkt, maar welke kleur het verschil maakt.
Chi-kwadraat onafhankelijkheid (kruistabel)
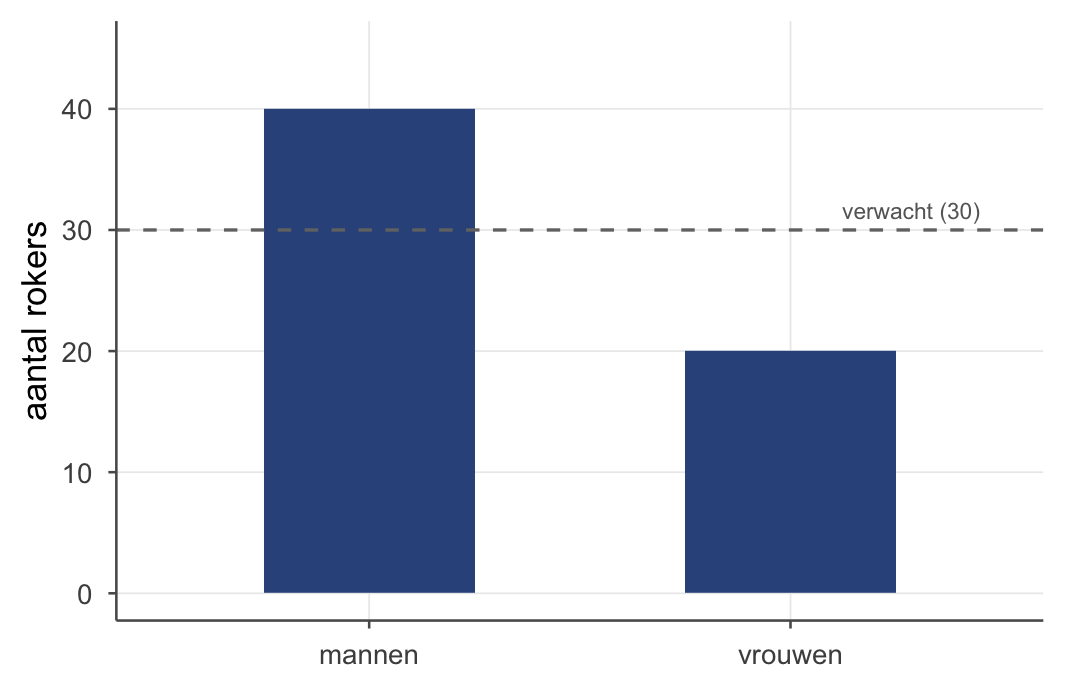
We vragen 400 mensen of ze roken, en noteren hun geslacht. Hier heeft iedereen al een onderbuikgevoel bij: roken mannen vaker? Vraag: hangt roken samen met geslacht?
| mannen |
40 |
160 |
200 |
| vrouwen |
20 |
180 |
200 |
| kolom-totaal |
60 |
340 |
400 |
Voel eerst wat “verwacht” betekent. In het algemeen rookt 60 van de 400 — 15% (iedereen die binnen kan wandelen én rookt). Stel nu dat roken en geslacht onafhankelijk zijn, dat het één niks met het ander te maken heeft: dan zou je verwachten dat in élke groep gewoon diezelfde 15% rookt. Je past die kans niet aan omdat er toevallig een man of een vrouw komt binnenwandelen. 200 mannen → je verwacht \({,}15 \cdot 200 = 30\) rokers. Maar er roken er 40. Méér dan verwacht — precies wat je onderbuik al fluisterde. En bij de vrouwen andersom: verwacht 30, geobserveerd 20, minder. Juist in dat gat tussen verwacht en geobserveerd zit het verhaal — en daar mag je van schrikken. Die verwachte aantallen zijn het meest informatief: heb je ze eenmaal, dan vertelt de rest zich vanzelf.
Het rekenen zelf is een beweging, geen formule om te stampen. Voor een cel: kijk naar zijn rijtotaal (opzij) en zijn kolomtotaal (omlaag), vermenigvuldig die twee, en deel door \(N\). Cel → rij → kolom → delen door \(N\).
- \(E\)(man, rookt) \(= \dfrac{200 \cdot 60}{400} = 30\) — precies die 15% van zojuist
- \(E\)(vrouw, rookt) \(= \dfrac{200 \cdot 60}{400} = 30\)
- \(E\)(man, niet) \(= \dfrac{200 \cdot 340}{400} = 170\), \(E\)(vrouw, niet) \(= 170\)
Eén ding, drie jasjes. Die 15% rokers is hetzelfde als de proportie \({,}15\), en dat is weer hetzelfde als de kans dat een willekeurige bezoeker rookt. Een percentage is gewoon een proportie maal honderd: \({,}15 \to 15\%\) (keer 100), \(15\% \to {,}15\) (deel door 100). Proportie en kans zijn één pot nat — allebei een getal tussen 0 en 1.
Daarom zijn er twee routes naar precies hetzelfde verwachte aantal:
- Korte route (de formule): \(E = \dfrac{\text{rijtotaal} \times \text{kolomtotaal}}{N} = \dfrac{60 \times 200}{400} = 30\).
- Lange route (via de proportie): bepaal eerst de proportie rokers over iederéén — \(\text{rijtotaal}/N = 60/400 = {,}15\) (= 15%) — en leg die over het kolomtotaal: \({,}15 \times 200 = 30\).
Ze geven hetzelfde, want \(\dfrac{\text{rij}}{N} \times \text{kolom} = \dfrac{\text{rij} \times \text{kolom}}{N}\). De lange route laat alleen zien wáár de formule vandaan komt: onder \(H_0\) rookt in élke groep diezelfde 15%.
De val (waar veel mensen op stuk lopen): die \({,}15\) is een proportie (15%), nog géén aantal. Het verwachte aantal krijg je pas ná het vermenigvuldigen met het kolomtotaal. Verwar die twee niet — en onthoud: een rijtotaal krijg je door de cellen op te tellen (\(40 + 20 = 60\)), niet te vermenigvuldigen.
Vervolgens \(\sum (O-E)^2/E\) over alle vier de cellen:
\[\chi^2 = \frac{(40-30)^2}{30} + \frac{(20-30)^2}{30} + \frac{(160-170)^2}{170} + \frac{(180-170)^2}{170}\] \[= 3{,}33 + 3{,}33 + 0{,}59 + 0{,}59 = 7{,}84\]
Ook hier volgt \(df\) uit het aantal categorieën — nu in twee richtingen: het aantal rijen en het aantal kolommen. Voor een kruistabel met \(r\) rijen en \(c\) kolommen: \(df = (r-1)(c-1)\). Hier een \(2 \times 2\)-tabel, dus \(df = 1 \cdot 1 = 1\). (Intuïtie: liggen de rij- en kolomtotalen vast, dan kun je nog \((r-1)(c-1)\) cellen vrij invullen; de rest volgt dwingend.) Kritieke waarde \(\chi^2_{.05, df=1} = 3{,}84\). Onze 7,84 is groter → verwerp de nulhypothese: roken hangt samen met geslacht — mannen roken vaker dan je onder onafhankelijkheid zou verwachten, precies wat iedereen al dacht.
Welke cel drijft dat? Weer de ruwe celresiduen \(\dfrac{O-E}{\sqrt{E}}\): de twee rookt-cellen springen eruit (\(\pm 1{,}83\): \(\tfrac{40-30}{\sqrt{30}} = +1{,}83\) bij mannen, \(-1{,}83\) bij vrouwen), terwijl de niet-rokers veel kleiner zijn (\(\pm 0{,}77\)). Daar — bij wie wél rookt — wijkt de werkelijkheid het sterkst van onafhankelijkheid af.
Die \(\dfrac{O-E}{\sqrt{E}}\) is een ruwe residu. Mooi, want z’n kwadraat is precies de celbijdrage aan \(\chi^2\) — maar hij heeft één vervelende eigenschap: zijn standaarddeviatie is niet 1. En je weet het inmiddels: ruw is ruk. Wil je ’m tegen \(\pm 1{,}96\) leggen (de \(z\) uit thema 3), dan moet hij éérst écht gestandaardiseerd worden.
Waarom is \(\sqrt{E}\) te groot? \(\sqrt{E}\) is de spreiding van een vrije cel — een telling die los mag fluctueren (variantie = gemiddelde = \(E\), zoals bij een vrij oplopende telling). Maar jouw cel is niet vrij. Hij hangt vast aan zijn rijtotaal en zijn kolomtotaal: die liggen vast, en dat bindt de cel. Een gebonden cel kan minder ver afdwalen dan een vrije, dus zijn echte spreiding is kleiner dan \(\sqrt{E}\). Deel je alleen door \(\sqrt{E}\), dan deel je door te véél → je residu wordt te klein → je bent te voorzichtig en mist échte uitschieters.
De gestandaardiseerde celresidu corrigeert dat: hij deelt óók door de bindingsfactor \(\sqrt{(1-\text{rij}/n)(1-\text{kol}/n)}\). Pas díé mag je als een gewone \(z\) aflezen.
Op de rokers. De man-rookt-cel: ruw \(\dfrac{40-30}{\sqrt{30}} = 1{,}83\) — netjes ónder ±2, je zou ’m bijna laten lopen.
Maar de bindingsfactor is \(\sqrt{\left(1-\tfrac{200}{400}\right)\left(1-\tfrac{60}{400}\right)} = \sqrt{0{,}5 \cdot 0{,}85} = 0{,}65\), en dus: \[\text{gestd. celresidu} = \frac{1{,}83}{0{,}65} = 2{,}80.\] Voorbij ±2 — wél een uitschieter. De ruwe versie had je ’m bijna laten missen.
En de cirkel sluit: weet je nog dat bij een \(2\times2\)-tabel \(\chi^2 = z^2\)? Dáár is die \(z\). \(\sqrt{7{,}84} = 2{,}80\), en \(2{,}80^2 = 7{,}84\). Rond. De ruwe 1,83 was alleen de cel z’n hapje van \(\chi^2\); de gestandaardiseerde 2,80 ís de hele \(z\).
Eén waarschuwing: \(\chi^2\) wordt vanzelf groter bij een grotere steekproef. Een hoge \(\chi^2\) betekent dus significant, niet automatisch een sterk verband — maten voor de sterkte (zoals Cramérs V) leer je later.
Strikvraag. \(\chi^2\) kent geen richting: door het kwadrateren telt elke afwijking — een cel té hoog of té laag — even hard mee. De toets vraagt niet “hoger of lager?” maar “wijkt het af, hoe dan ook?”. In die zin is \(\chi^2\) stiekem tweezijdig (bij meer dan twee categorieën eigenlijk: alle kanten tegelijk).
Maar juist omdat beide kanten al in dat kwadraat zitten, lees je één staart (de rechter) en doe je nooit ×2 — de “keer 2” van een tweezijdige z-toets is hier al gedaan door het kwadrateren.
Mooiste bewijs: bij deze \(2 \times 2\)-tabel (\(df = 1\)) is het létterlijk tweezijdig. Daar geldt \(\chi^2 = z^2\), en de rechterstaart-kans van \(\chi^2\) is exact de tweezijdige \(p\) van die \(z\). De ×2 zit er dus echt al in.
- OV: hangen twee variabelen samen? (Of, bij GOF: past de verdeling van één variabele bij wat we verwachten?)
- \(H_0\): onafhankelijkheid (of: past bij verwachte verdeling). \(H_1\): hangt samen (of: wijkt af).
- Toetskeuze: chi-kwadraat (onafhankelijkheid of goodness-of-fit).
- Onder \(H_0\): bereken de verwachte aantallen per cel.
- Toetsingsgrootheid: \(\chi^2 = \sum (O-E)^2/E\).
- df = \((r-1)(c-1)\) voor kruistabel (\(r\) rijen, \(c\) kolommen); \(k-1\) voor goodness-of-fit (\(k\) categorieën).
- Vergelijk met \(\chi^2_{\alpha, df}\) in de tabel.
- Conclusie: de samenhang tussen X en Y — zeg wélk verband (richting en welke cellen beoordeel je uit de tabel en de residuen, niet uit \(\chi^2\) zelf).
Data om mee te spelen: roken_geslacht.sav en egel_pelskleur.sav — of de hele zip. Met de hand snap je nu wat er gebeurt; in SPSS doe je dezelfde toets met twee categorische variabelen.
Analyze → Descriptive Statistics → Crosstabs → één variabele naar Row(s), de andere naar Column(s) → Statistics… → Chi-square aanvinken → Continue → OK.
Je leest de toets af in de regel Pearson Chi-Square: de waarde van \(\chi^2\), \(df\) en de bijbehorende kans (Asymptotic Significance).
De val van Simpson — een verband dat omkeert
Alles wat we sinds correlatie (thema 5) doen heeft één gevaar: een globaal verband kan subgroepen verbergen. Een kruistabel laat het globale plaatje zien. Maar soms verbergt dat plaatje een omgekeerd verband dat binnen subgroepen leeft. Dat is Simpson’s paradox, en je moet ’m kennen — anders trek je serieus de verkeerde conclusie.
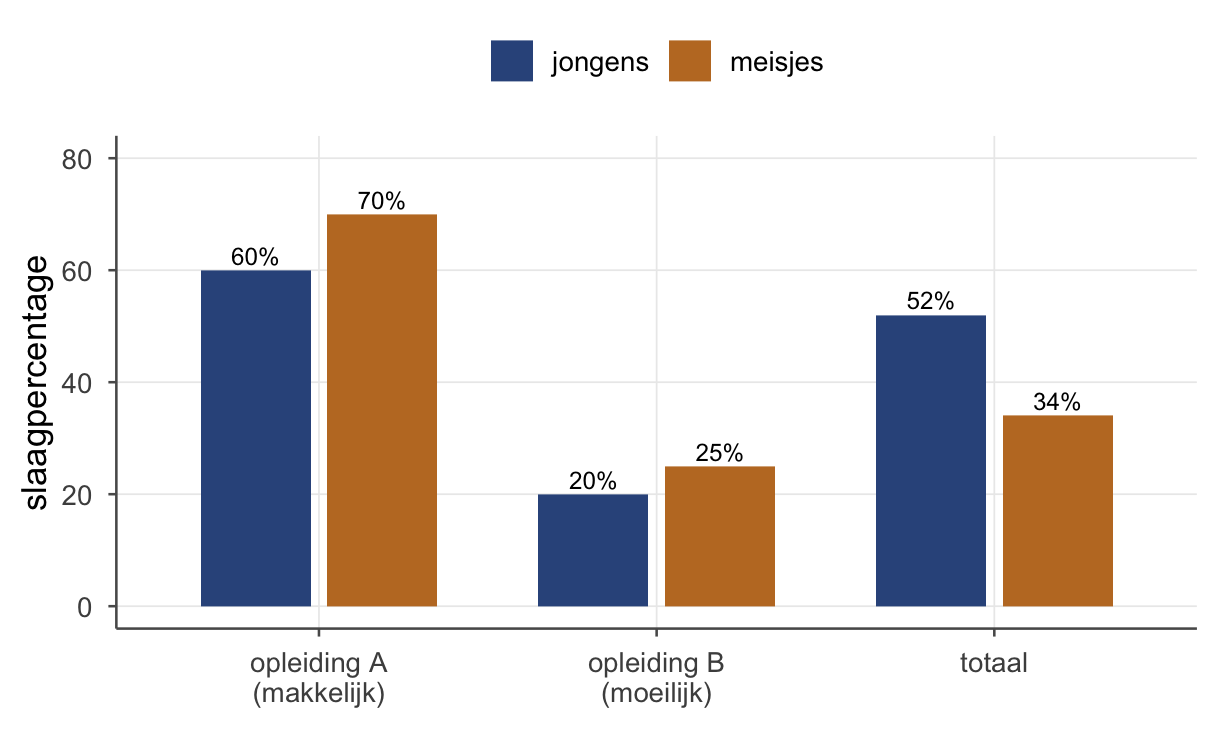
Een universiteit kijkt naar de slaagpercentages van jongens en meisjes bij twee opleidingen.
Opleiding A (makkelijk): jongens 480/800 = 60% geslaagd; meisjes 140/200 = 70% geslaagd. → meisjes scoren beter.
Opleiding B (moeilijk): jongens 40/200 = 20% geslaagd; meisjes 200/800 = 25% geslaagd. → meisjes scoren beter.
Totaal: jongens 520/1000 = 52%; meisjes 340/1000 = 34%. → jongens scoren beter ?!
Binnen elke opleiding doen meisjes het beter; maar in het totaal lijken jongens beter. Hoe kan dat? Doordat de groepen zich anders verdelen over de opleidingen. Veel meisjes deden de moeilijke opleiding (waar iederéén slechter scoort), en veel jongens de makkelijke. Dat trekt het meisjes-gemiddelde naar beneden en het jongens-gemiddelde omhoog.
Een derde variabele (hier: opleiding) die met beide andere samenhangt, kan een verband doen kantelen. Aggregeer dus nooit zonder na te denken: kijk altijd binnen relevante subgroepen. Dit is ook precies wat een covariaat doet in latere analyses — controleren voor zo’n meelopende variabele.
Oefenen
Honderd egels worden in drie hokken gezet (links / midden / rechts). Onder \(H_0\) verwachten we gelijke voorkeur. Telling: links 25, midden 50, rechts 25.
Bereken \(\chi^2\).
Met \(df = 2\) en \(\chi^2_{.05} = 5{,}99\) — verwerpen?
(a) \(E = 100/3 \approx 33{,}33\) per hok. Per hok \((O-E)^2/E\):
- links: \((25-33{,}33)^2/33{,}33 = 2{,}08\)
- midden: \((50-33{,}33)^2/33{,}33 = 8{,}33\)
- rechts: idem links \(= 2{,}08\)
\(\chi^2 = 2{,}08 + 8{,}33 + 2{,}08 = 12{,}5\).
(b) \(12{,}5 > 5{,}99\) → verwerpen. De egels hebben een sterke voorkeur voor het middelste hok.
Data: egel_hok.sav — 100 egels, één kolom hok (1 = links, 2 = midden, 3 = rechts; links 25, midden 50, rechts 25).
Dit is een goodness-of-fit (één variabele tegen een verwachte verdeling), dus niet Crosstabs maar: Analyze → Nonparametric Tests → Legacy Dialogs → Chi-square → zet hok bij Test Variable List → onder Expected Values staat All categories equal (de gelijke verdeling uit \(H_0\)) → OK.
Aflezen: Chi-Square = 12,50, df = 2, Asymp. Sig. = ,002 — exact je handwerk (\(\chi^2 = 12{,}5\)), en ruim onder .05, dus verwerpen. (De data staat hier al uitgeklapt — 1 rij per egel — zodat je niets hoeft te wegen. Had je een teltabel met 3 rijen, dan eerst Data → Weight Cases op de aantallen-kolom.)
Een schoolinspecteur bekijkt twee scholen op één-jaars-doorstroom. School X: 80%. School Y: 65%. School X lijkt beter. Maar binnen elke leerlingcategorie (laag / hoog vooropleidingsniveau) doet School Y het juist iets beter. Hoe kan dat?
School X heeft waarschijnlijk veel meer leerlingen met een hoog vooropleidingsniveau (die sowieso vaker doorstromen, op elke school). Het aggregaatcijfer reflecteert dus vooral de samenstelling van de leerlingen, niet de kwaliteit van de school. Net als bij Simpson: een meelopende derde variabele (vooropleiding) verklaart het schijnverschil. Wie scholen eerlijk wil vergelijken, vergelijkt binnen vooropleidingsniveau — niet over de hoofden heen.
In het bos is aan 300 dieren gevraagd of ze bang zijn voor onweer. Alleen de randtotalen staan vast:
| ja |
? |
? |
120 |
| nee |
? |
? |
180 |
| kolom-totaal |
180 |
120 |
300 |
Welk deel van alle dieren is bang voor onweer? Geef je antwoord als proportie én als percentage.
Onder \(H_0\) (bang-zijn staat los van soort): hoeveel dassen verwacht je die bang zijn? Doe het via de proportie-route (proportie \(\times\) kolomtotaal).
Controleer met de formule \(\dfrac{\text{rijtotaal} \times \text{kolomtotaal}}{N}\) — krijg je hetzelfde?
Een medestudent zegt: “die ,40 ís het verwachte aantal bange dassen.” Klopt dat? Leg in één zin uit.
(a) \(120/300 = {,}40\), oftewel 40% is bang voor onweer (proportie \({,}40\) = percentage 40% = de kans dat een willekeurig dier bang is).
(b) Onder \(H_0\) is in élke soort 40% bang. Dassen: \({,}40 \times 180 = \mathbf{72}\).
(c) \(\dfrac{120 \times 180}{300} = \dfrac{21600}{300} = 72\). Hetzelfde — want \(\dfrac{120}{300} \times 180 = \dfrac{120 \times 180}{300}\).
(d) Nee. \({,}40\) is een proportie (40%), géén aantal. Het verwachte aantal is \({,}40 \times 180 = 72\) — je moet de proportie eerst nog over het kolomtotaal leggen.
Is er in het bos een verband tussen pootvoorkeur (rechts / links / nog geen) en soort (das / uil)? Bij 200 jonge dieren:
| rechts |
60 |
50 |
110 |
| links |
15 |
16 |
31 |
| nog geen |
25 |
34 |
59 |
| kolom-totaal |
100 |
100 |
200 |
Toets op \(\alpha = .05\).
- \(H_0\): geen verband (soort en pootvoorkeur onafhankelijk)
- \(H_1\): wel verband
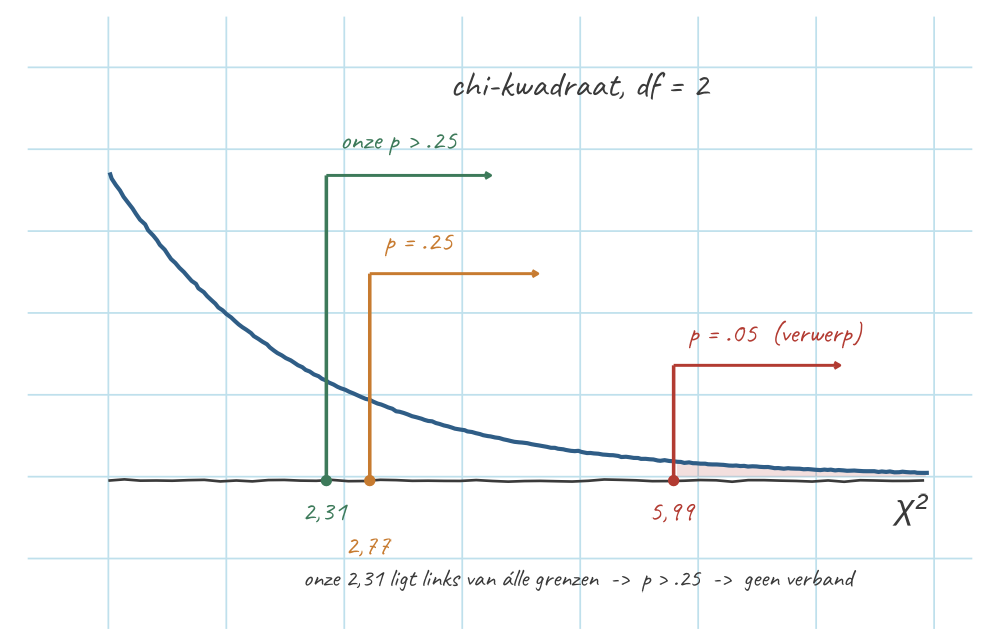
- \(\chi^2 = 2{,}31\) · \(df = (3-1)(2-1) = 2\)
- \(\chi^2\)-tabel (rechterstaart): \(2{,}31 <\) de .25-grens (\(2{,}77\)) → \(p > .25\)
- \(p > \alpha\ (.05)\) → \(H_0\) niet verwerpen
- Antwoord: geen significant verband tussen soort en pootvoorkeur
- \(H_0\) / \(H_1\) (elk op een regel):
\(H_0\) = geen verband (onafhankelijk)
\(H_1\) = wel verband (afhankelijk).
- Verwachte waarde per cel \(= \dfrac{\text{rijtotaal} \times \text{kolomtotaal}}{N}\). Beide kolommen zijn hier 100, dus per rij:
- rechts: \(110 \times 100 / 200 = 55\) (das én uil)
- links: \(31 \times 100 / 200 = 15{,}5\)
- nog geen: \(59 \times 100 / 200 = 29{,}5\)
- \(\chi^2\) per cel — in een tabel, zo zie je elke stap terug:
| rechts, das |
60 |
55 |
0,455 |
| rechts, uil |
50 |
55 |
0,455 |
| links, das |
15 |
15,5 |
0,016 |
| links, uil |
16 |
15,5 |
0,016 |
| nog geen, das |
25 |
29,5 |
0,686 |
| nog geen, uil |
34 |
29,5 |
0,686 |
| \(\Sigma = \chi^2\) |
|
|
2,31 |
- \(df\) \(= (\text{rijen} - 1)(\text{kolommen} - 1) = (3-1)(2-1) = \mathbf{2}\).
- Opzoeken in de \(\chi^2\)-tabel — altijd de rechterstaart (richtingloos, nooit ×2): \(2{,}31\) ligt vóór \(2{,}77\) (de .25-grens bij \(df = 2\)) → \(p > .25\).
- Beslissen: \(p > \alpha\ (.05)\) → \(H_0\) niet verwerpen.
- Conclusie: er is geen significant verband tussen soort en pootvoorkeur; de kleine verschillen zijn toeval.
Tot slot
Geen gemiddelden meer, gewoon tellen — maar onder de motorkap is er niks veranderd. Je zet wat je ziet (\(O\)) naast wat het model verwacht (\(E\)), en in dat gat ertussen zit het hele verhaal. Te groot een gat, gekwadrateerd en opgeteld, en je gooit “het is toeval” overboord. De fiets in de bakker, nu in een kruistabel. En onthoud dat ene: \(\chi^2\) kent geen richting, alles wordt gekwadrateerd, dus nooit Pippi.
En dan Simpson, helemaal aan het eind, als een waarschuwing die je nooit meer kwijtraakt: aggregeren is een vorm van vergeten. De subgroepen zwijgen niet — je hoort ze alleen niet meer.
Werkboek OZP 1 · Thema 11, versie 0.1 (handrekenen & theorie). Doorlopend voorbeeld: de egels (+ alledaagse voorbeelden: roken, school).
Terug naar boven