Van dubbele pijl naar enkele pijl
In thema 5 vonden we een verband tussen leeftijd en lengte van de egels — een dubbele pijl, zonder richting. Nu zetten we er een enkele pijl op: we gaan lengte voorspellen uit leeftijd. Dat is regressie.
Onthoud het woord regressie hier als: we brengen een ingewikkelde puntenwolk terug tot iets eenvoudigs — een lijn. De variatie in lengte proberen we zo goed mogelijk te vangen met de variatie in leeftijd.
Mijn vader vertelde verhalen met eindeloze bijzinnen vóór hij bij de clou kwam — pas op het eind wist je waar het heen ging. Doe dat in de statistiek niet. Begin met de afhankelijke variabele: wat wil je verklaren? De lengte. En pas dán: waarmee? De leeftijd. “Wij willen lengte voorspellen aan de hand van leeftijd” — meteen helder.
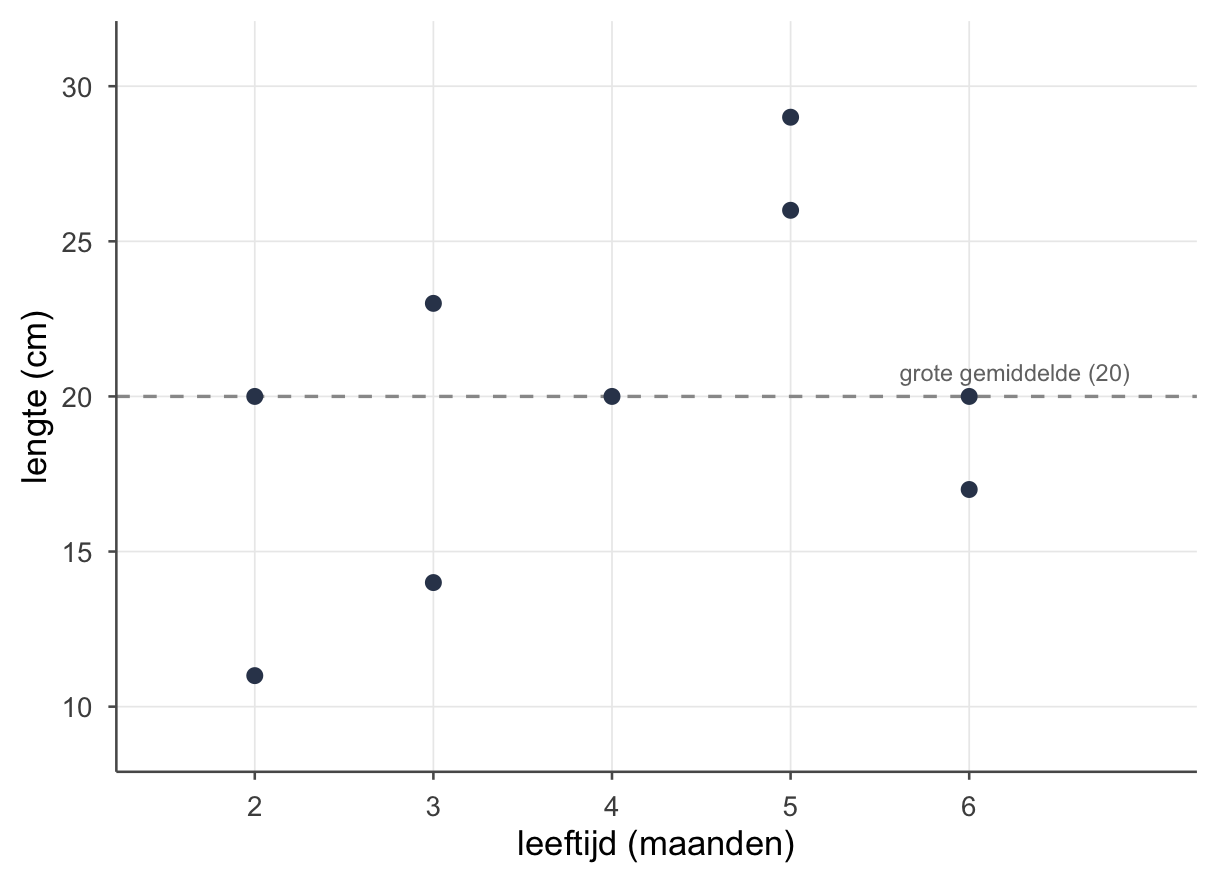
Zonder verdere info is je beste gok voor een binnenwandelende egel het grote gemiddelde: 20 cm (Deel 1). Verklap ik je z’n leeftijd, dan kun je het beter — via een lijn. Het hele hoofdstuk draait om die ene vraag: hoeveel beter wordt je gok, en wat doe je met wat je dan nóg mist? Aan het eind splitsen we die misser eerlijk op in DATA = FIT + RESIDU — maar eerst de data, de wolk, en de lijn.
De data nog even op een rij
Voor we iets tekenen: de negen egels uit thema 5 weer even op tafel — leeftijd (maanden) tegen lengte (cm).
| 1 |
2 |
11 |
| 2 |
2 |
20 |
| 3 |
3 |
14 |
| 4 |
3 |
23 |
| 5 |
4 |
20 |
| 6 |
5 |
26 |
| 7 |
5 |
29 |
| 8 |
6 |
17 |
| 9 |
6 |
20 |
Het grote gemiddelde is \(\bar{y} = 20\) cm (de gemiddelde lengte), en de gemiddelde leeftijd \(\bar{x} = 4\) maanden. Egel 4 (jong maar lang) en egel 8 (oud maar kort) waren onze dwarsliggers tegen de trend; het verband was matig — \(r_{xy} \approx {,}42\) (thema 5).
De puntenwolk
Teken die negen punten — lengte tegen leeftijd — en je ziet meteen wat een tabel verbergt: een wolk die schuin omhoog loopt. Oudere egels zijn gemiddeld wat langer, maar het is geen strakke streep; er zit flink wat ruis omheen. De stippellijn is je oude gok: het grote gemiddelde (20), gelijk voor elke egel.
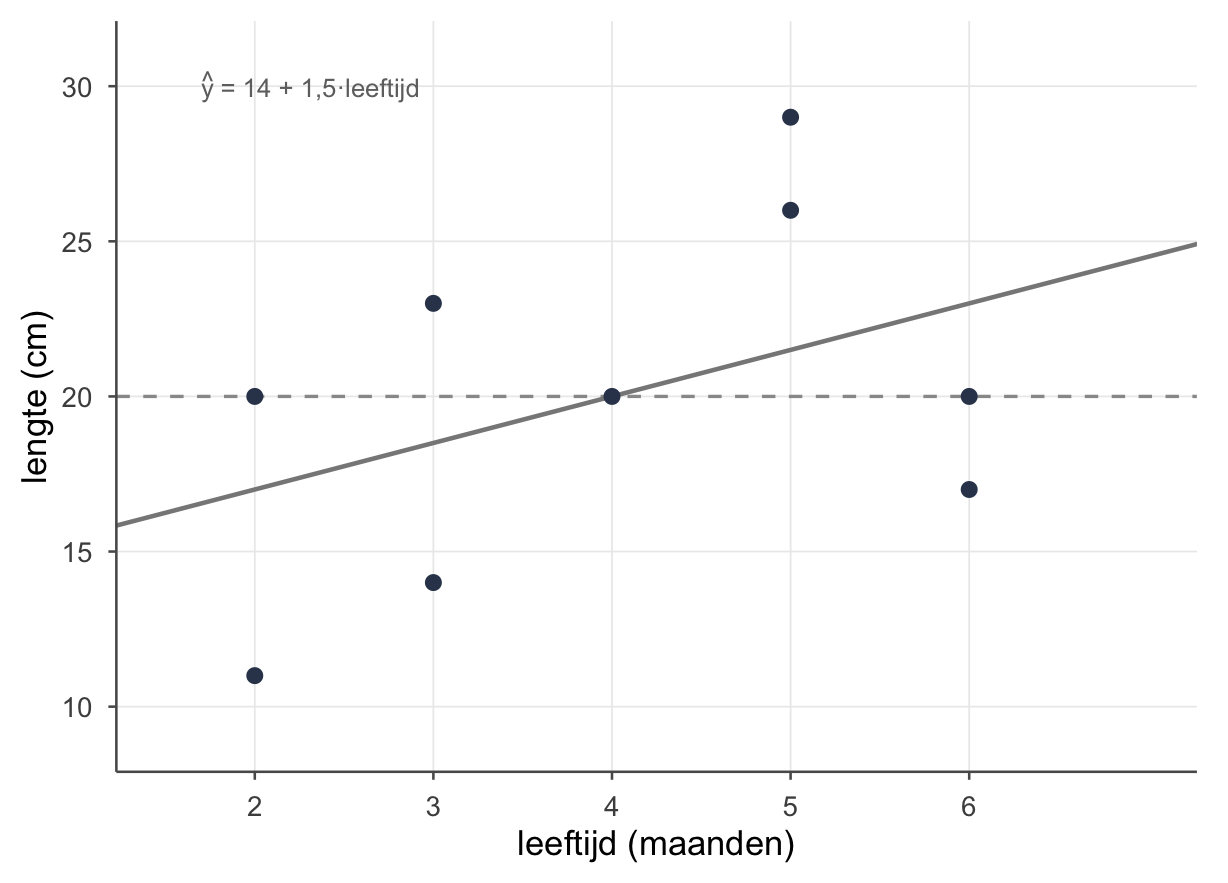
De regressielijn
Nu leggen we de best passende lijn door die wolk — de lijn die de punten zo goed mogelijk vangt. Voor onze egels is dat \(\hat{y} = 14 + 1{,}5\,x\) (zo dadelijk reken je ’m zelf uit):
De lijn loopt schuin omhoog met helling 1,5: twee egels die één maand in leeftijd schelen, verschillen gemiddeld 1,5 cm in lengte — de oudere is de langere. Let op het werkwoord: egels die ouder zíjn, niet “een egel die ouder wordt”. Onze data zijn een momentopname van negen verschillende egels, geen filmpje van één egel die opgroeit; de helling vergelijkt egels onderling, hij volgt er geen één door de tijd.
De lijn berekenen
Waar komen die 14 en 1,5 vandaan? De lijn is \(\hat{y} = b_0 + b_1 x\), met \(b_0\) het intercept (startwaarde) en \(b_1\) de helling. Begin met de helling — die bouw je uit de covariantie-motor van thema 5: hoeveel gezamenlijke beweging er is, vergeleken met hoeveel \(x\) in z’n eentje beweegt.
\[b_1 = r_{xy}\cdot\frac{s_y}{s_x} = \frac{s_{xy}}{s_x^2} = \frac{3{,}75}{2{,}5} = 1{,}5\]
(Let op: \(s_y\) bóven, \(s_x\) onder — een klassieke tentamenval.) Dan het intercept. De lijn moet door het zwaartepunt \((\bar{x}, \bar{y})\) van de wolk lopen, dus reken je terug:
\[b_0 = \bar{y} - b_1\,\bar{x} = 20 - 1{,}5\cdot 4 = 14\]
Samen: \(\hat{y} = 14 + 1{,}5\,x\). De lijn start (rekenkundig) op 14 — dat betekent níét dat een pasgeboren egel (leeftijd 0) precies 14 cm is; het is het rekenkundige startpunt, ver buiten het bereik van onze data.
Voorspellen en residuen
Vul een leeftijd in en je hebt een voorspelling; trek die van de echte lengte af en je hebt het residu \(e = y - \hat{y}\) — wat het model mist.
| 1 |
2 |
11 |
17 |
−6 |
| 2 |
2 |
20 |
17 |
+3 |
| 3 |
3 |
14 |
18,5 |
−4,5 |
| 4 |
3 |
23 |
18,5 |
+4,5 |
| 5 |
4 |
20 |
20 |
0 |
| 6 |
5 |
26 |
21,5 |
+4,5 |
| 7 |
5 |
29 |
21,5 |
+7,5 |
| 8 |
6 |
17 |
23 |
−6 |
| 9 |
6 |
20 |
23 |
−3 |
| Σ (som) |
36 |
180 |
180 |
0 |
Een positief residu = de egel is langer dan de lijn voorspelt (punt boven de lijn); negatief = eronder. Kijk naar de somrij onderaan, daar zie je iets moois: de voorspellingen tellen op tot precíés dezelfde totale lengte als de metingen (\(\sum \hat{y} = \sum y = 180\)), en dus tellen de residuen samen op tot nul (\(\sum e = 0\)). Ook opgeteld klopt DATA = FIT + RESIDU dan netjes: \(180 = 180 + 0\). De lijn ligt eerlijk in het midden — net zoveel gewicht erboven als eronder. Onze dwarsliggers uit thema 5 — egel 4 (jong maar lang, \(+4{,}5\)) en egel 8 (oud maar kort, \(-6\)) — wijken flink af tegen de trend in. (Verwar over- en onderschatting niet: kijk altijd wat ten opzichte van wat — de echte waarde ten opzichte van de voorspelling.)
Data om mee te spelen: egels.sav — of de hele zip. Met de hand heb je \(b_0\) en \(b_1\) nu zelf gevonden; SPSS hoest dezelfde lijn in twee klikken op.
Analyze → Regression → Linear → lengte naar Dependent, leeftijd naar Independent(s) → OK.
Aflezen: het intercept (14) en de helling (1,5) staan in de tabel Coefficients onder B; de verklaarde variantie (\(R^2 \approx {,}18\)) in de tabel Model Summary.
Het spelletje: DATA = FIT + RESIDU
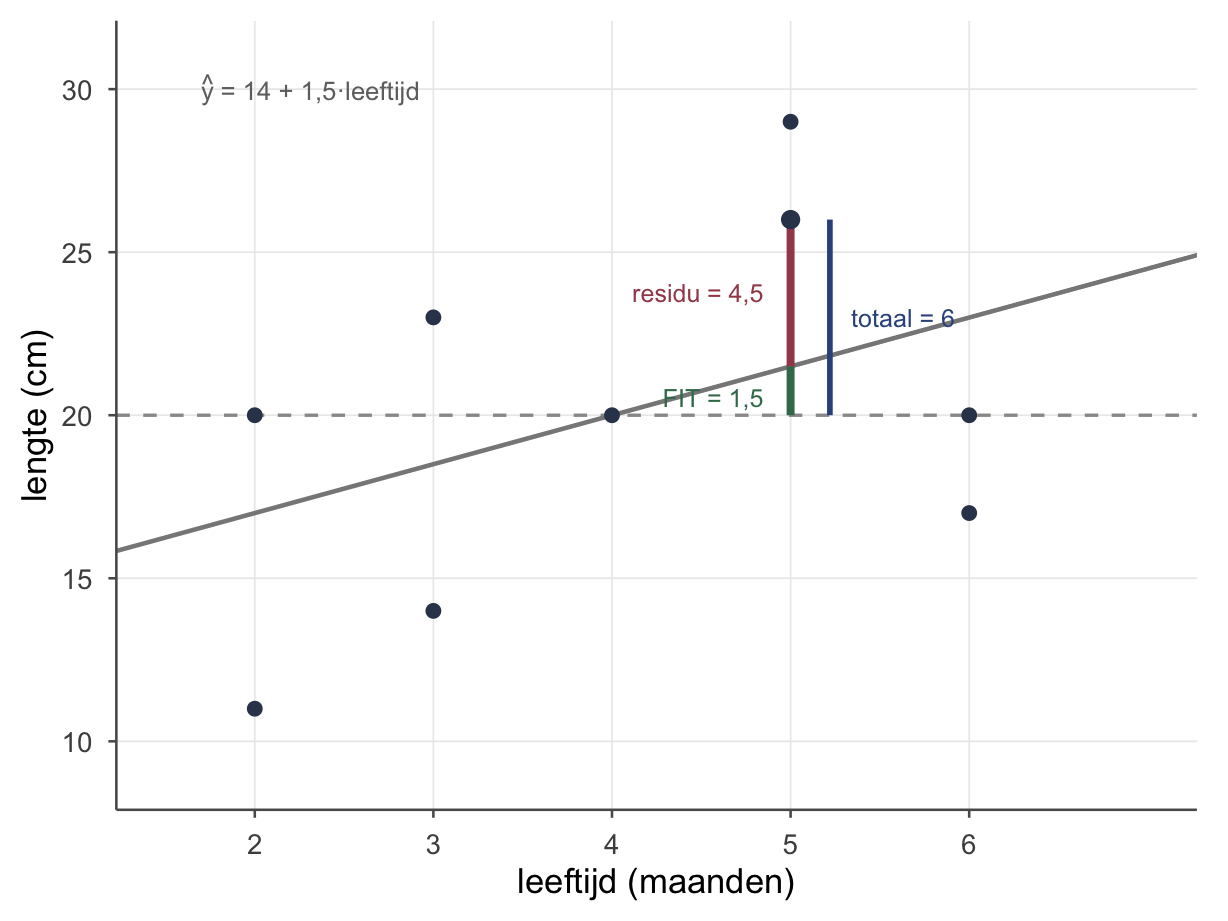
Nu we per egel kunnen voorspellen, kunnen we de gok-fout opsplitsen. Neem egel 6 uit de tabel hierboven (5 maanden, 26 cm). We vergelijken eigenlijk twee gokken: de domme gok (iedereen 20 cm — het grote gemiddelde) en de slimme gok (de lijn, \(\hat{y} = 21{,}5\)). We splitsen zijn afstand tot het grote gemiddelde in twee stukken:
\[\underbrace{(y - \bar{y})}_{\text{totale gok-fout}} \;=\; \underbrace{(\hat{y} - \bar{y})}_{\text{wat de lijn verklaart}} \;+\; \underbrace{(y - \hat{y})}_{\text{wat overblijft (residu)}}\]
Oftewel: DATA = FIT + RESIDU. Voor onze egel: de totale gok-fout is \(26 - 20 = 6\); daarvan verklaart de lijn \(21{,}5 - 20 = 1{,}5\); en er blijft \(26 - 21{,}5 = 4{,}5\) over. En inderdaad: \(6 = 1{,}5 + 4{,}5\).
Op het spreidingsdiagram hieronder teken je deze drie als streepjes: het totale streepje (naar het grote gemiddelde), het stuk dat de lijn ophoest, en het restje van het punt tot de lijn. Elk een kleur: blauw = totaal, groen = verklaard, bordeaux = residu. Wie dit spelletje snapt, kan straks regressie én variantieanalyse bijna zonder formules — het is steeds deze opsplitsing.
In symbolen is ditzelfde de regressievergelijking: je gemeten waarde is de voorspelling van de lijn plus wat overblijft.
\[\text{DATA} = \text{FIT} + \text{RESIDU} \qquad\Longrightarrow\qquad Y = \hat{Y} + e \;=\; b_0 + b_1 X + e\]
DATA is je gemeten \(Y\), FIT de voorspelling \(\hat{Y} = b_0 + b_1 X\), en RESIDU het stukje \(e = Y - \hat{Y}\) dat de lijn mist.
In je steekproef schrijf je \(Y = b_0 + b_1 X + e\). In de populatie — die je nooit helemaal ziet — heet diezelfde lijn met Griekse letters:
\[Y = \beta_0 + \beta_1 X + \varepsilon\]
De steekproef-gewichten \(b_0, b_1\) schatten de populatie-waarden \(\beta_0, \beta_1\), en het residu \(e\) schat de echte fout \(\varepsilon\) — dezelfde Latijn-schat-Grieks-gedachte als \(s\) die \(\sigma\) schat (thema 9). En dit is allemaal nog ruw (ongestandaardiseerd): \(b_0\) en \(b_1\) hangen aan de eenheden, cm en maanden. De gestandaardiseerde versie, met \(z\)-scores, zie je zo.
Subtiel maar eerlijk: hierboven is FIT de hele voorspelling \(\hat{Y}\) (\(= 21{,}5\) voor onze egel); in de figuur splitsen we juist de afstand tot het gemiddelde (\(Y - \bar{Y}\)), en daar is de groene FIT het stuk \(\hat{Y} - \bar{Y} = 1{,}5\) dat de lijn bóven het grote gemiddelde toevoegt. Hetzelfde residu (\(e = 4{,}5\)), ander vertrekpunt.
Hoe goed past het model?
Een model is een vereenvoudiging van de werkelijkheid — net als een kledingmaat. Een spijkerbroek heeft twee parameters (lengte, wijdte, “28/32”) en past redelijk. Een maatpak heeft veel meer parameters en past beter. Zo ook hier: het allersimpelste model is het grote gemiddelde (één parameter); de regressielijn voegt er één toe (de helling) en past beter. Hoe complexer het model, hoe beter het past — op déze data. Maar een maatpak dat perfect om de huidige persoon zit, past de vólgende niet per se beter; of een complexer model ook écht beter is (en niet alleen toevallig), is een andere vraag (voor later).
De verklaarde variantie is \(r_{xy}^2 \approx {,}18\) (uit thema 5): de lijn verklaart maar zo’n 18% van de variatie in lengte, 82% blijft in de residuen zitten. Dat zag je net in de figuur: voor onze voorbeeld-egel was de FIT (1,5) klein en het residu (4,5) groot. Een matig verband geeft een lijn die iets helpt, maar lang niet alles vangt — en dat is eerlijk.
Je zag net dat de drie streepjes (\(y-\bar{y}\), \(\hat{y}-\bar{y}\), \(y-\hat{y}\)) per egel optellen, en dat de residuen samen nul zijn (de somrij). Net als bij de variantie in thema 1 heffen plus en min elkaar dan op — dus kwadrateer je eerst, en tél je daarna op over alle negen egels. DATA = FIT + RESIDU wordt dan:
\[\underbrace{\textstyle\sum (y-\bar{y})^2}_{\text{SST (totaal)}} \;=\; \underbrace{\textstyle\sum (\hat{y}-\bar{y})^2}_{\text{SSM (model / FIT)}} \;+\; \underbrace{\textstyle\sum (y-\hat{y})^2}_{\text{SSE (error / residu)}}\]
Voor onze egels: \(\text{SST} = 252\), \(\text{SSM} = 45\), \(\text{SSE} = 207\) — en inderdaad \(252 = 45 + 207\). Hieruit krijg je de verklaarde variantie langs een tweede weg:
\[R^2 = \frac{\text{SSM}}{\text{SST}} = \frac{45}{252} \approx {,}18\]
Exact dezelfde \({,}18\) als \(r_{xy}^2 = {,}42^2\). Twee wegen, één antwoord — want \(R^2\) is niets anders dan “welk deel van de totale variatie (SST) vangt het model (SSM)”.
Let op: op de collegesheets van 2026 staat alleen \(R^2 = r^2\); deze SST/SSM/SSE-opsplitsing is dáár geen tentamenstof — je hoeft ’m niet uit je hoofd te leren. Maar onthoud dát het bestaat: in OZP 2 (en elke zwaardere analyse, zoals variantieanalyse) komt deze sum of squares-opsplitsing keihard terug. Het ís dit DATA = FIT + RESIDU-spelletje, gekwadrateerd en opgeteld.
Pas op
- Niet doortrekken buiten bereik (extrapolatie). Onze egels zijn 2 tot 6 maanden oud. Worden ze bij 60 maanden 76 cm? Natuurlijk niet — de lijn geldt alleen binnen het gemeten gebied.
- Causaliteit. Net als bij correlatie: de richting (lengte uit leeftijd) is een gekozen richting, geen bewijs van oorzaak. We hadden ook leeftijd uit lengte kunnen voorspellen.
- Negatieve \(r\) → negatieve helling. Een consistentiecheck: het teken van \(b_1\) volgt het teken van \(r_{xy}\).
Gestandaardiseerde regressie
Net als \(b_1\) “ruw” is (afhankelijk van eenheden), kun je ook met z-scores werken. Dan voorspel je \(z_y\) uit \(z_x\), en het intercept valt weg (het wordt 0). Het gestandaardiseerde gewicht is bij enkelvoudige regressie precies de correlatie:
\[\hat{z}_y = r_{xy}\cdot z_x = {,}42\, z_x\]
“Ga je 1 standaardafwijking omhoog op leeftijd, dan ga je gemiddeld 0,42 standaardafwijking omhoog op lengte.” Ruw is ruk; gestandaardiseerd is vergelijkbaar.
Oefenen
Met \(\hat{y} = 14 + 1{,}5x\):
Wat is de voorspelde lengte van een egel van 5 maanden?
Een egel van 3 maanden blijkt 20 cm. Wat is zijn residu, en zit hij boven of onder de lijn?
(a) \(\hat{y} = 14 + 1{,}5\cdot 5 = 21{,}5\) cm.
(b) \(\hat{y} = 14 + 1{,}5\cdot 3 = 18{,}5\); residu \(e = 20 - 18{,}5 = +1{,}5\). Positief → de egel is langer dan voorspeld → hij ligt boven de lijn.
Data: egels.sav — de negen doorlopende egels, kolommen leeftijd en lengte.
Analyze → Regression → Linear → lengte naar Dependent, leeftijd naar Independent(s) → OK.
Aflezen: in de tabel Coefficients, kolom B, staat het intercept (Constant) = 14,00 en de helling (leeftijd) = 1,50. Daarmee voorspel je zelf: een egel van 5 maanden → \(14 + 1{,}5 \cdot 5 = 21{,}5\) cm — exact je handwerk.
Voor de egel van 3 maanden uit T6.1 (lengte 20, \(\hat{y}=18{,}5\)): splits zijn afstand tot het grote gemiddelde (20) in het verklaarde deel en het residu. Klopt DATA = FIT + RESIDU?
Totale afstand tot \(\bar{y}\): \(20 - 20 = 0\). Verklaard door de lijn: \(\hat{y} - \bar{y} = 18{,}5 - 20 = -1{,}5\). Residu: \(y - \hat{y} = 20 - 18{,}5 = +1{,}5\). Check: \(0 = -1{,}5 + 1{,}5\). Klopt — de lijn trekt ’m iets naar beneden (jong → korter verwacht), het residu duwt ’m weer terug omhoog.
Data: egels.sav — dezelfde negen egels.
Analyze → Regression → Linear (zelfde opzet als T6.1) → knop Save… → onder Residuals vink je Unstandardized aan → Continue → OK. SPSS zet nu een nieuwe kolom RES_1 (\(y - \hat{y}\)) in je databestand.
Aflezen: voor elke egel zie je het residu — bijv. de twee dwarsliggers (jong-maar-lang, oud-maar-kort) hebben de grootste residuen, net als in de tabel hierboven. Let op: de egel uit deze opgave (3 maanden, lengte 20) zit níét in dit groepje — die is hypothetisch. Voor de echte 3-maanders in de data (lengte 14 en 23) lees je residu \(-4{,}5\) en \(+4{,}5\) af; het \(+1{,}5\) uit de opgave reken je zelf met \(\hat{y} = 18{,}5\).
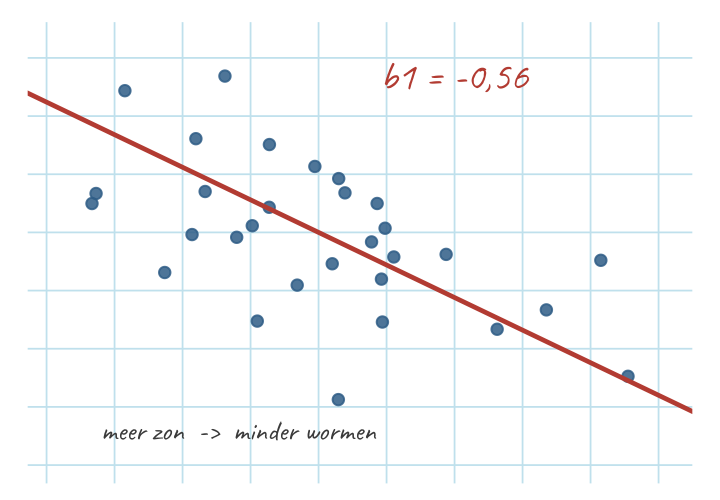
Een onderzoekertje voorspelt bij de mollen het aantal gevonden wormen per dag (\(y\)) uit het aantal uren dat een mol bovengronds in de zon zit (\(x\)). De kleinste-kwadratenlijn geeft helling \(b_1 = -0{,}56\).
Wat betekent dit getal — in gewone taal, mét richting?
Drie dierenbos-collega’s roepen elk iets. Wie heeft gelijk, en waar zitten de anderen fout?
- Mol A: “Min? Dan levert ‘uren in de zon’ dus géén bijdrage aan het voorspellen van wormen.”
- Mol B: “Dat kan niet, er zit een rekenfout in — een helling hoort tussen 0 en 1 te liggen.”
- Mol C: “Een negatieve helling betekent dat de verklaarde variantie laag is.”
- \(b_1 = -0{,}56\): per extra uur in de zon daalt de voorspelde wormenvangst gemiddeld met \(0{,}56\) worm.
- Negatieve helling → de lijn loopt van linksboven naar rechtsonder: meer \(x\) hoort bij minder \(\hat{y}\).
- Mol A fout: er ís een verband, juist een negatief. “Geen bijdrage” zou \(b_1 = 0\) betekenen (vlakke lijn) — en \(-0{,}56 \neq 0\).
- Mol B fout: een helling mag élk teken en élke grootte hebben; hij draagt de eenheden (worm per uur). Tussen \(-1\) en \(+1\) zit de correlatie, niet de helling.
- Mol C fout: het teken zegt niets over de verklaarde variantie (\(r^2\)). Richting en sterkte zijn twee losse dingen.
- Antwoord: de helling is negatief én betekenisvol; alleen de richting is omgekeerd.
Één getal, drie verwarringen. De truc: haal richting, grootte en sterkte uit elkaar — dat zijn drie verschillende vragen.
- Lees het teken eerst — de richting. Min betekent een negatief verband: de lijn dáált. Van linksboven naar rechtsonder. Mollen die méér uren in de zon zitten, vangen naar verwachting minder wormen. (Consistentiecheck: dat teken volgt het teken van \(r_{xy}\) — zie Pas op.)
- Lees de grootte — hoe steil. \(|b_1| = 0{,}56\) is de “zoveel per eenheid”: elk extra uur in de zon → \(0{,}56\) worm minder in de voorspelling. Dit is nog ruw (ongestandaardiseerd) — het hangt aan de eenheden uur en worm.
- Mol A weerleggen. “Geen bijdrage” zou een vlakke lijn zijn, \(b_1 = 0\): \(x\) doet er dan niet toe. Maar \(-0{,}56\) is geen nul; er is juist wél samenhang, alleen de andere kant op. Negatief ≠ afwezig.
- Mol B weerleggen. Mol B verwart de helling met de correlatie. De correlatie \(r\) is gestandaardiseerd en zit altijd tussen \(-1\) en \(+1\); de helling \(b_1\) draagt de eenheden en mag élk getal zijn — \(-0{,}56\), maar net zo goed \(-40\) of \(+1000\). “Moet tussen 0 en 1” is een klassieke tentamenval: dat geldt hooguit voor \(r^2\), niet voor een helling.
- Mol C weerleggen. Het teken van de helling en de verklaarde variantie staan los van elkaar. Bij precies dezelfde helling \(-0{,}56\) kan \(r^2\) hoog zijn (punten strak om de lijn) óf laag (punten wijd eromheen). Richting (het teken) zegt niets over sterkte (\(r^2\)) — hetzelfde onderscheid als bij correlatie in thema 5.
Val op: richting, grootte en sterkte zijn drie aparte vragen. Het teken (\(-\)) beantwoordt alleen de eerste (dalend), de \(0{,}56\) de tweede (hoe steil), en pas \(r^2\) de derde (hoe goed de lijn past). Wie ze op één hoop gooit, trapt in Mol A, B of C.
Wat blijft liggen
Hier stopt het voor nu. In een vervolgcursus voeg je méér voorspellers toe (meervoudige regressie) — de sum of squares-opsplitsing uit het kader hierboven (\(\text{SST} = \text{SSM} + \text{SSE}\)) blijft dan precies werken, alleen met meer streepjes. Het is steeds dit DATA = FIT + RESIDU-spelletje, voor de hele dataset tegelijk.
Tot slot
Het oude model — gok het grote gemiddelde, iedereen 20 — gooien we niet weg; we bouwen erop. Vertel me de leeftijd erbij, en de lijn doet het nét iets beter. Niet veel beter, eerlijk gezegd: de FIT was 1,5 en het residu 4,5, de lijn vangt zo’n 18% en mist de rest. Maar dat is geen falen, dat is hoe het is. DATA = FIT + RESIDU — wat je modelleert plus wat je laat liggen, en dat tweede stuk lieg je nooit weg. Onthoud dit spelletje goed, want de zware modellen die nog komen zijn allemaal ditzelfde, alleen met meer streepjes.
Werkboek OZP 1 · Thema 6, versie 0.2 (handrekenen & theorie). Doorlopend voorbeeld: de egels.
Terug naar boven